Redis持久化的取舍和选择
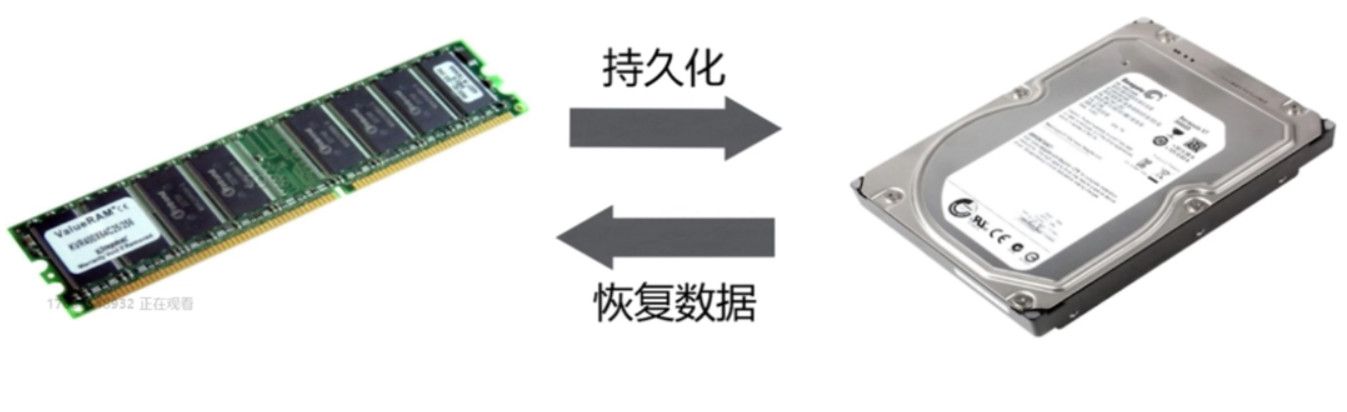
持久化的作用
什么是持久化
- Redis所有数据保存在内存中, 对数据的更新异步的保存到磁盘上就是持久化.
持久化的方式
- 快照
- 把某个状态的数据信息拍一张’照片’, 保存在磁盘上, 保存的是某个时刻的数据信息
- 例: MySQL Dump, Redis RDB使用的是这种方式
- 写日志
- 数据库数据进行任何的更新, 将以写日志的方式保存. 当需要恢复时, 把日志信息重新’走一遍’就可恢复数据的状态.
- 例: MySQL Biglog, Hbase Hlog, Redis AOF使用的是这种方式
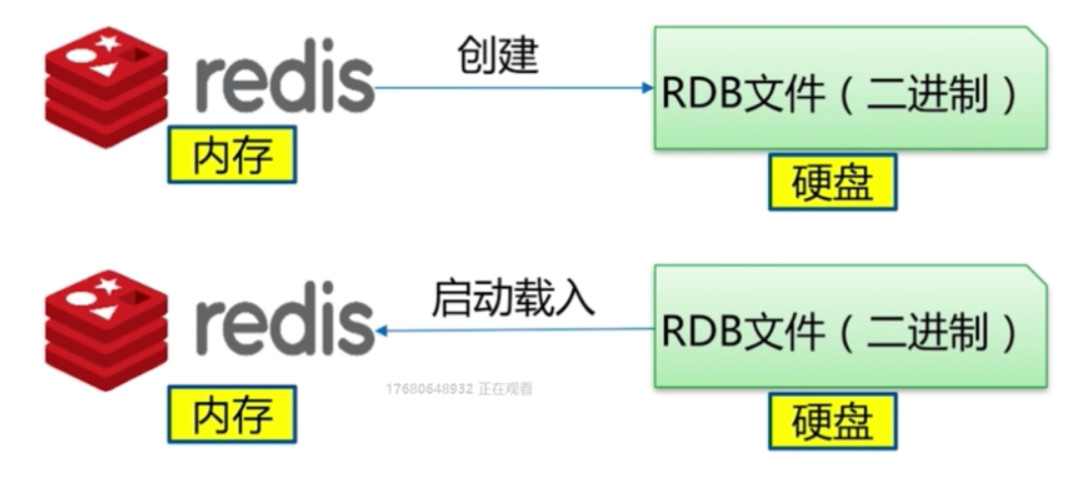
RDB
什么是RDB
- redis数据保存在内存中, 当使用生成RDB的命令可以将redis内存中数据保存为磁盘上的RDB文件
- RDB文件可以用来做数据备份及数据恢复.
- RDB文件也是复制的媒介.(Redis主从复制)
触发机制
- save (同步)
- bgsave (异步)
- 自动 (某些条件达到时自动生成RDB文件)
save命令
- save命令是一个同步的命令, 当数据量很大时可能造成阻塞.
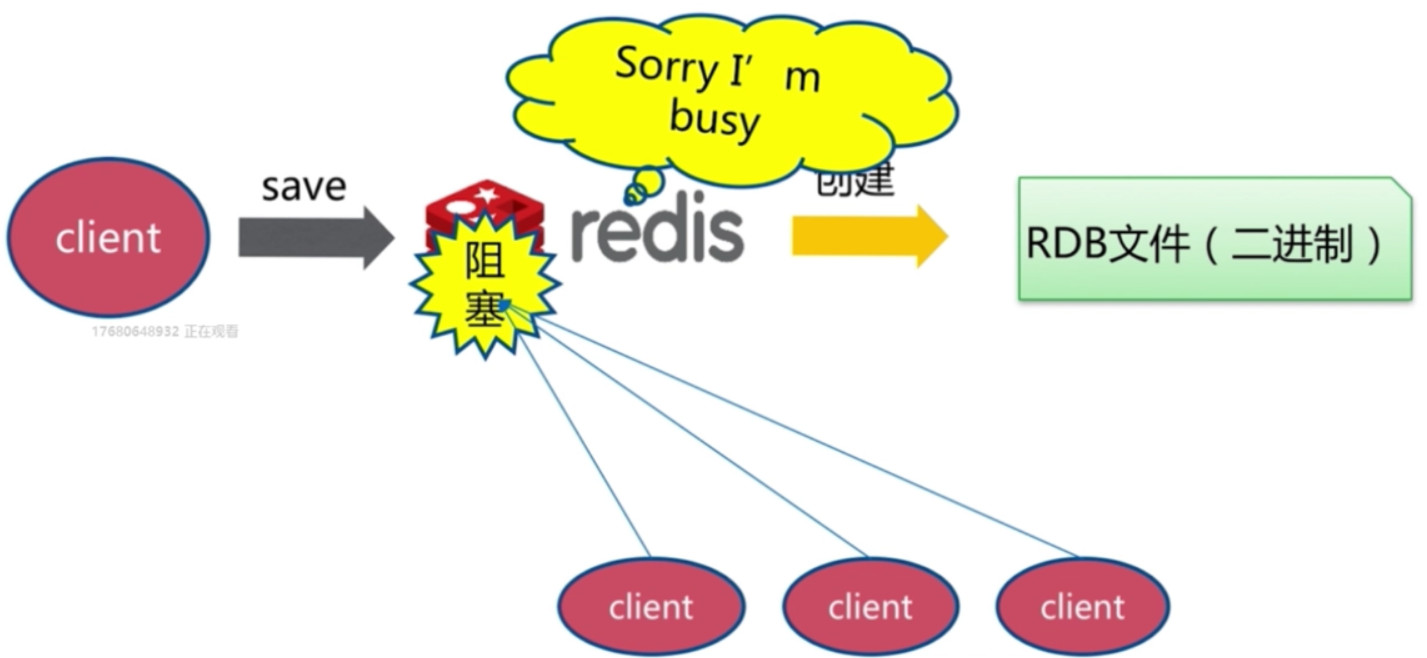
- 文件策略: 执行命令时会把Redis内存中数据保存为一个临时的文件, 保存成功后删除旧的文件然后用新的文件代替之.
- 复杂度: O(n)
bgsave命令
- bgsave命令是一个异步的命令, 当执行此命令时会利用redis的fork()函数生成一个子进程.
- fork()函数是非常快的, 但是极少情况下可能会出现慢的情况, 此时也有可能造成阻塞.
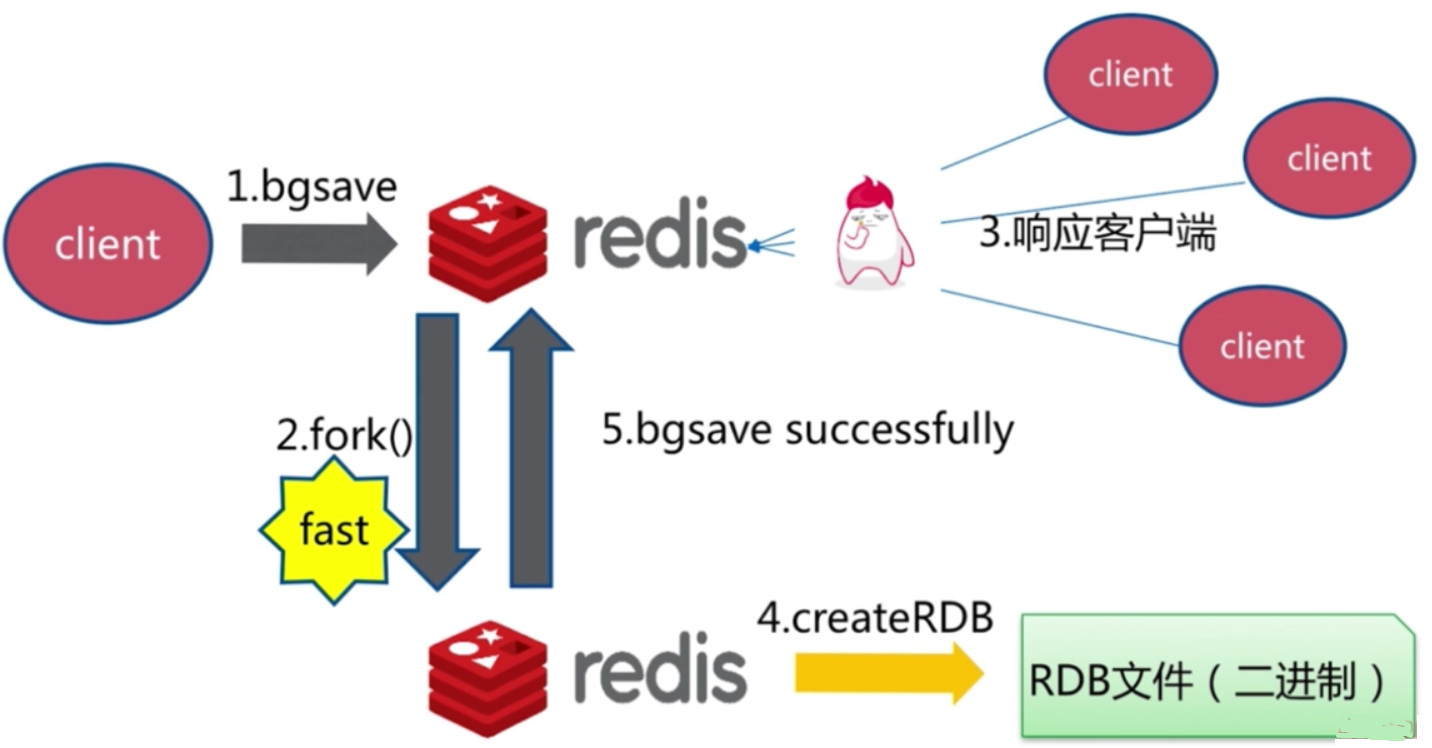
- 文件策略和复杂度和save命令相同
save与bgsave
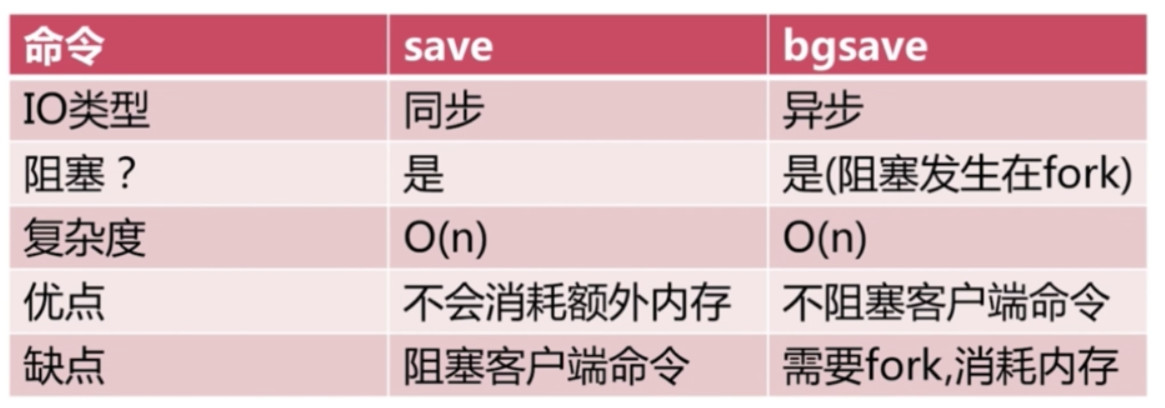
注: bgsave不阻塞客户端命令(不阻塞是带引号的, 因为fork()会发生阻塞, 但通常很短的时间)
自动生成RDB
- Redis提供了一个配置使其自动生成RDB
- 默认配置解释: 每900s 有1条改变|每300s 有10条改变|每60秒有10000条改变, 都会触发Redis自动生成RDB文件(内部使用bgsave命令).
- 不是一种很好的方式, 写入时机不好控制(虽然能设置配置条件, 但无法满足实际需求).
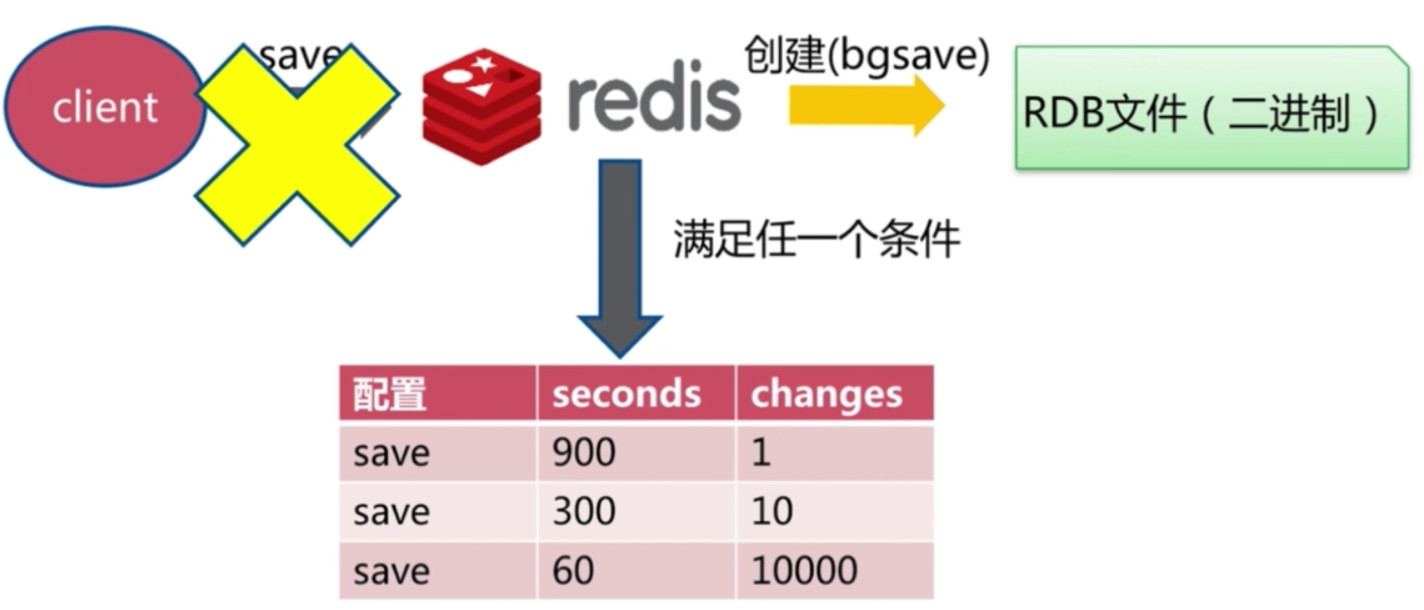
关于RDB配置
- Redis默认关于RDB文件的配置
# 关于自动生成RDB文件的策略
save 900 1
save 300 10
save 60 10000
# 默认生成RDB文件名称 (包括执行save命令, bgsave命令, 自动生成RDB)
dbfilename dump.rdb
# 生成RDB文件位置
dir ./
# 在使用bgsave生成RDB文件出错时是否停止生成RDB文件
stop-writes-on-bgsave-error yes
# 生成的RDB文件是否采用压缩的格式
rdbcompression yes
# 是否对RDB文件进行校验和的检验
rdbchecksum yes- 最佳配置
dbfilename采用根据运行端口进行命令. (因为Redis是单线程, 所以通常一台机器会跑几个Redis进程, 通过这种命令方式, 避免各个进程之间的Redis生成的RDB文件造成覆写)dir选择一个大磁盘路径rdbcompression一般进行压缩, 方便进行主从复制

触发机制 - 不容忽视的方式
全量复制
当进行主从复制时, Redis会自动生成一个RDB文件用于主从复制
debug reload
当Redis使用debug方式进行重启时, 会生成一个RDB文件用于重启后的数据恢复
shutdown
此命令有一个
-save参数, 该参数会把Redis内存中的数据保存为RDB文件后进行关闭
试验
- 试验前配置
[root@localhost redis]# mkdir data
[root@localhost redis]# mkdir config
[root@localhost redis]# cp redis.conf ./config/redis-6379.conf
[root@localhost redis]# pwd
/usr/local/soft/redis
[root@localhost redis]# vim ./config/redis-6379.conf
# 修改redis-6379.conf文件的如下内容
# ---------------------------#
# 以守护进程的方式启动redis-server
daemonize yes
# 日志文件名
logfile "6379.log"
# 禁用掉自动生成RDB
#save 900 1
#save 300 10
#save 60 10000
# 生成的RDB文件名
dbfilename dump-6379.rdb
# ---------------------------#save阻塞
- 生成5000000条测试数据
127.0.0.1:6379> debug populate 5000000
OK
(21.25s)
127.0.0.1:6379> dbsize
(integer) 5000000
127.0.0.1:6379> info memory
# Memory
used_memory:627908040
used_memory_human:598.82M
used_memory_rss:647372800
used_memory_peak:627908040
used_memory_peak_human:598.82M
used_memory_lua:36864
mem_fragmentation_ratio:1.03
mem_allocator:jemalloc-3.6.0
- 另开一个终端, 输入如下命令 (get hello在下一步再运行)
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello- 在本终端运行save命令, 然后在上一个终端运行get命令, 查看save命令是否阻塞
# 终端1
127.0.0.1:6379> save
OK
(7.38s)
# 终端2
127.0.0.1:6379> get hello
"world"
(5.76s)由上可见, save命令是一个阻塞命令.上诉情况在生产中是不可接受的
- 查看生成的RDB文件
[root@localhost redis]# cd data/
[root@localhost data]# ll
总用量 129672
-rw-r--r--. 1 root root 2306 4月 19 00:40 6379.log
-rw-r--r--. 1 root root 132777813 4月 19 00:40 dump-6379.rdbbgsave fork
- 验证bgsave非阻塞
# 在运行终端1的命令行立刻转到终端2运行命令
# 终端1
127.0.0.1:6379> bgsave
Background saving started
# 终端2
127.0.0.1:6379> get hello
"world"
[root@localhost data]# tail 6379.log
16995:M 19 Apr 00:46:04.613 * Background saving started by pid 17243
17243:C 19 Apr 00:46:12.022 * DB saved on disk
17243:C 19 Apr 00:46:12.024 * RDB: 8 MB of memory used by copy-on-write
16995:M 19 Apr 00:46:12.035 * Background saving terminated with success可见, bgsave命令不会阻塞redis-cli而影响其他命令的执行
- 验证bgsave会fork一个子进程
# 在运行终端1的命令行立刻转到终端2运行命令
# 终端1
127.0.0.1:6379> bgsave
Background saving started
# 终端2
[root@localhost data]# ps -aux | grep redis- | grep -v "redis-cli" | grep -v "grep"
root 16995 2.1 16.3 763492 632228 ? Ssl 00:28 0:30 redis-server *:6379
root 17384 96.6 16.3 763496 631256 ? R 00:51 0:02 redis-rdb-bgsave *:6379
[root@localhost data]# ps -aux | grep redis- | grep -v "redis-cli" | grep -v "grep"
root 16995 2.1 16.3 763492 632228 ? Ssl 00:28 0:30 redis-server *:6379可见, 执行bgsave命令是, Redis会fork一个子进程进行保存RDB文件的操作
- 验证Redis生成RDB的文件策略
# 在运行终端1的命令行立刻转到终端2运行命令
# 终端1
127.0.0.1:6379> bgsave
Background saving started
# 终端2
[root@localhost data]# ll
总用量 260680
-rw-r--r--. 1 root root 2895 4月 19 00:55 6379.log
-rw-r--r--. 1 root root 132777813 4月 19 00:51 dump-6379.rdb
-rw-r--r--. 1 root root 121151488 4月 19 00:55 temp-17444.rdb
[root@localhost data]# ll
总用量 129672
-rw-r--r--. 1 root root 3086 4月 19 00:55 6379.log
-rw-r--r--. 1 root root 132777813 4月 19 00:55 dump-6379.rdb
可见, Redis生成RDB的文件策略是执行命令时会把Redis内存中数据保存为一个临时的文件, 保存成功后删除旧的文件然后用新的文件代替之.
真的自动?
- 设置配置文件如下内容, 并执行如下命令
save 60 5[root@localhost data]# vim ../config/redis-6379.conf
[root@localhost data]# redis-server ../config/redis-6379.conf
[root@localhost data]# redis-cli
127.0.0.1:6379> dbsize
(integer) 0
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> set c d
OK
127.0.0.1:6379> set e f
OK
127.0.0.1:6379> set g h
OK
127.0.0.1:6379> set i j
OK
127.0.0.1:6379> exit
[root@localhost data]# ll
总用量 12
-rw-r--r--. 1 root root 5914 4月 19 01:08 6379.log
-rw-r--r--. 1 root root 33 4月 19 01:08 dump-6379.rdb
[root@localhost data]# tail 6379.log
17668:M 19 Apr 01:08:36.050 * 5 changes in 60 seconds. Saving...
17668:M 19 Apr 01:08:36.052 * Background saving started by pid 17686
17686:C 19 Apr 01:08:36.071 * DB saved on disk
17686:C 19 Apr 01:08:36.072 * RDB: 4 MB of memory used by copy-on-write
17668:M 19 Apr 01:08:36.152 * Background saving terminated with success
17668:M 19 Apr 01:09:37.041 * 5 changes in 60 seconds. Saving...
17668:M 19 Apr 01:09:37.043 * Background saving started by pid 17708
17708:C 19 Apr 01:09:37.044 * DB saved on disk
17708:C 19 Apr 01:09:37.045 * RDB: 4 MB of memory used by copy-on-write
17668:M 19 Apr 01:09:37.144 * Background saving terminated with success
可见, 在满足RDB自动生成配置后, redis自动生成了RDB文件
RDB长啥样?
[root@localhost data]# cat dump-6379.rdb
REDIS0006�ijhelloworldcdabefgh���9�ɺ�RDB总结
- RDB是Redis内存到硬盘的快照, 用于持久化
- save通常会阻塞Redis
- bgsave不会阻塞Redis, 但会fork新进程
- save自动配置满足任一就会被执行
- 有些RDB触发机制不容忽视
AOF
RDB有什么问题
耗时, 耗性能
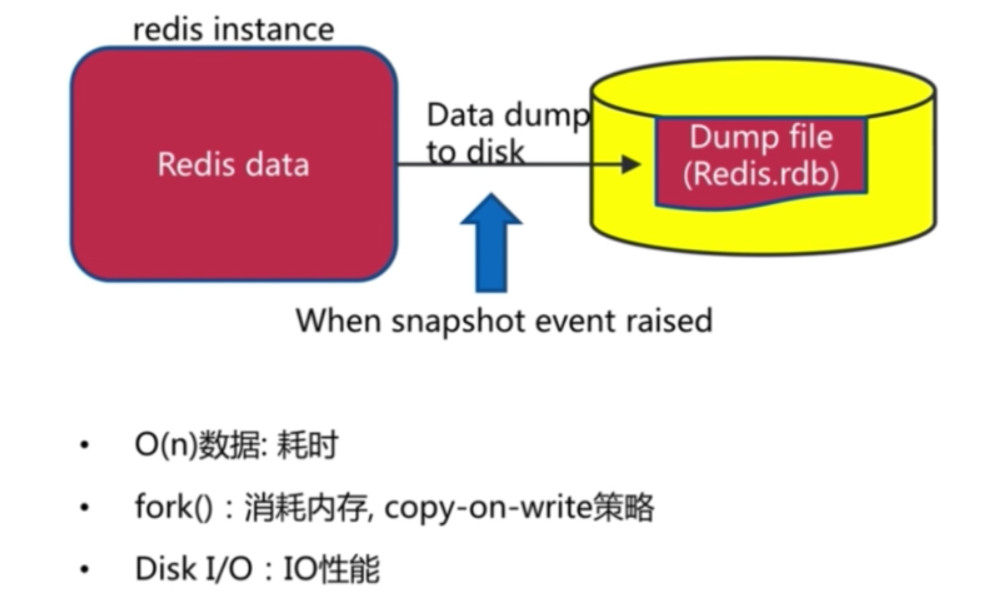
不可控, 丢失数据

什么是AOF
AOF运行原理 - 创建
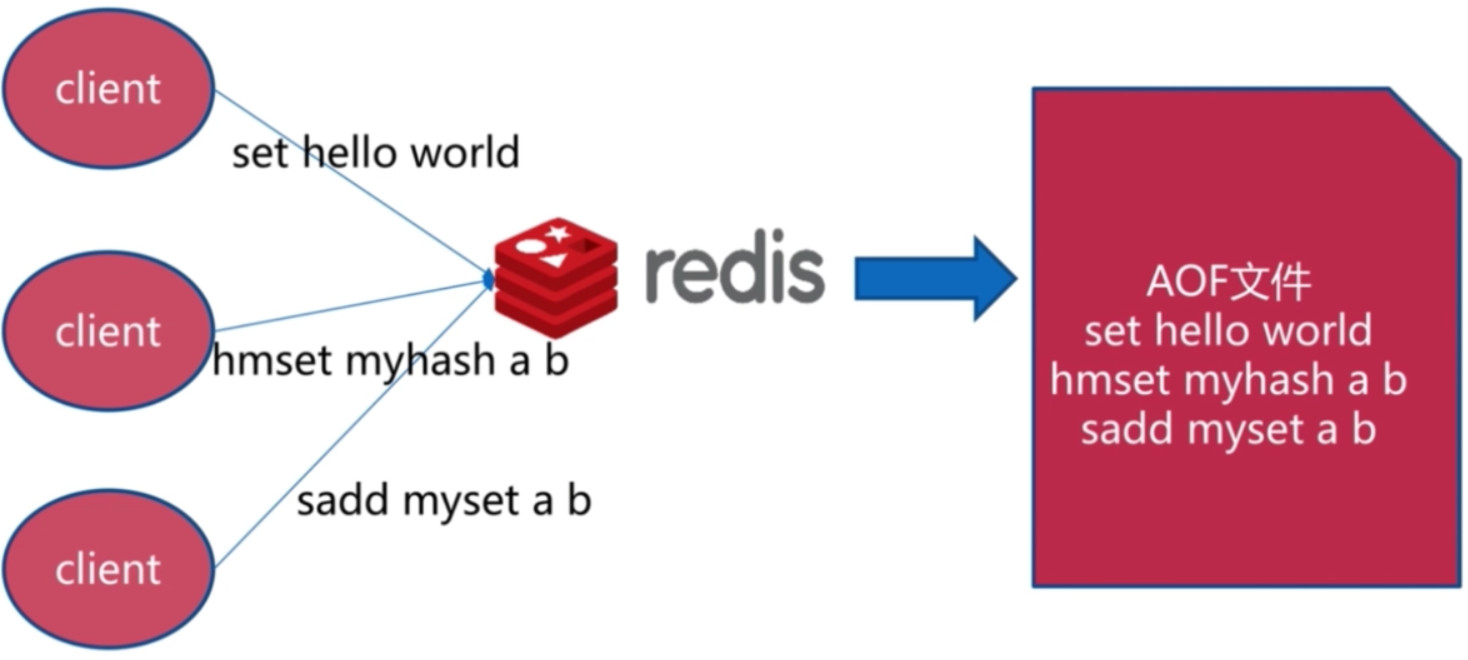
注: 上述AOF存储内容只是为了演示方便, 实际存储内容并不是那样
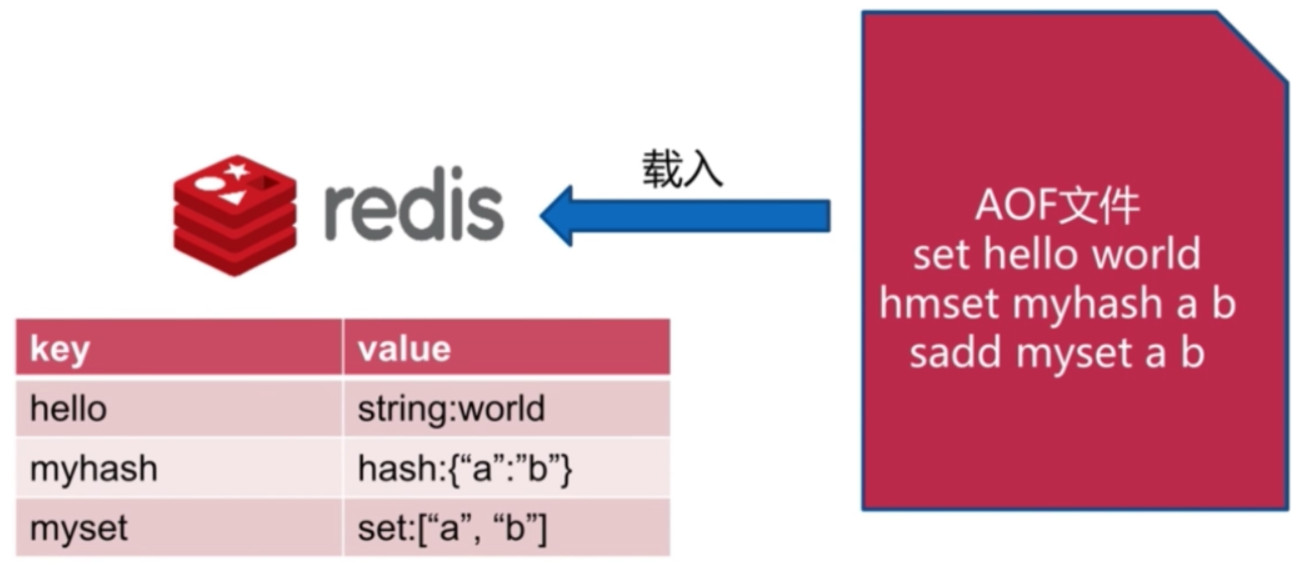
AOF运行原理 - 恢复
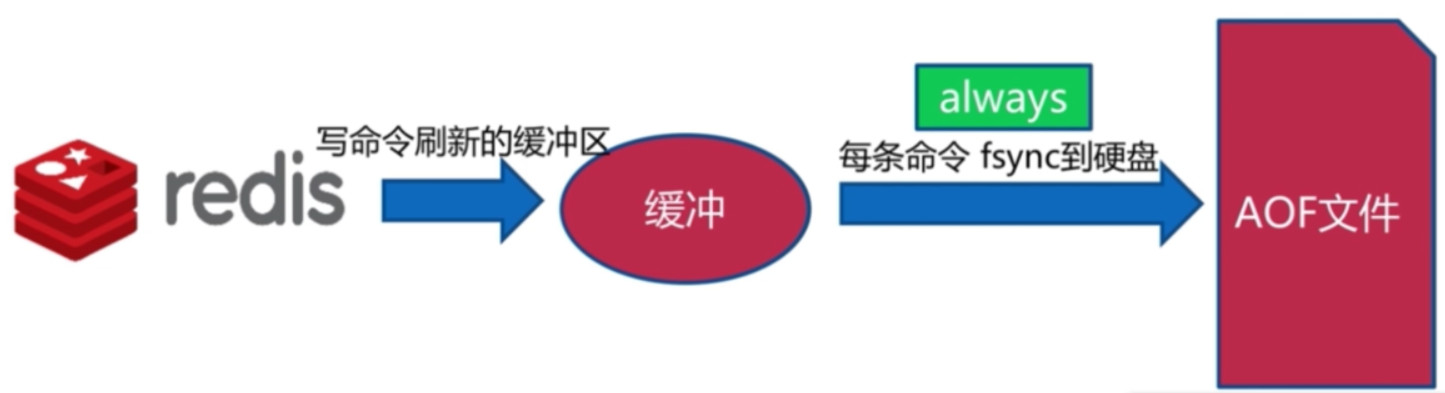
AOF的三种策略
always
- 每条命令都会触发Redis的fsync到硬盘, 这样就不会有数据丢失
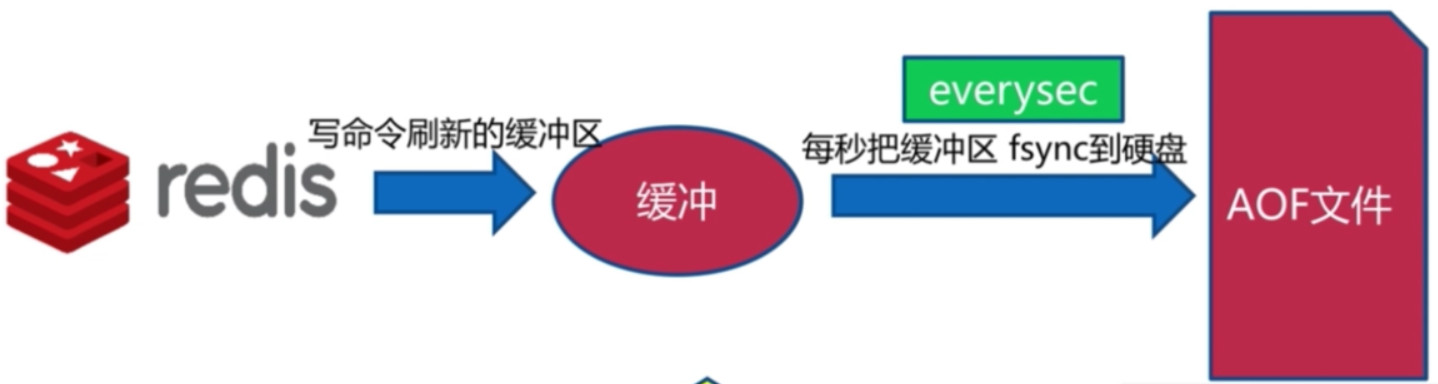
everysec (默认)
- 每秒触发Redis的fsync到硬盘, 这样可以起到保护硬盘的作用
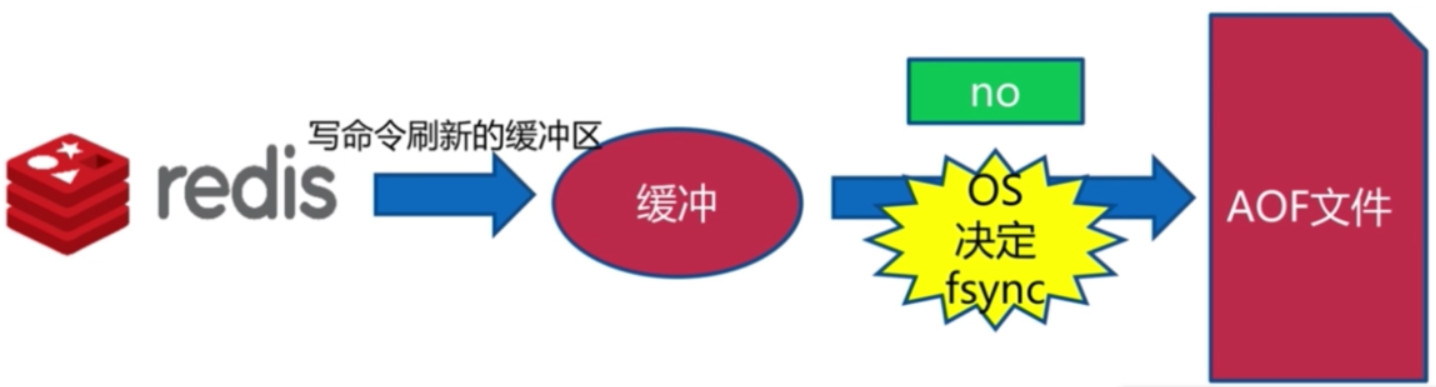
no
- 操作系统决定触发Redis的fsync到硬盘
三种策略选择
- 一般使用默认的everysec (具体根据实际应用场景)

AOF重写
- AOF重写就是把过期的, 没有用的, 重复的, 可以优化的命令化简, 使得AOF文件变小

AOF重写作用
- 减少磁盘占用量
- 加速恢复速度
AOF重写实现两种方式
- bgrewriteaof
- 和bgsave类似, fork一个子进程进行重写
- AOF重写配置
- 实现自动重写
bgrewriteaof
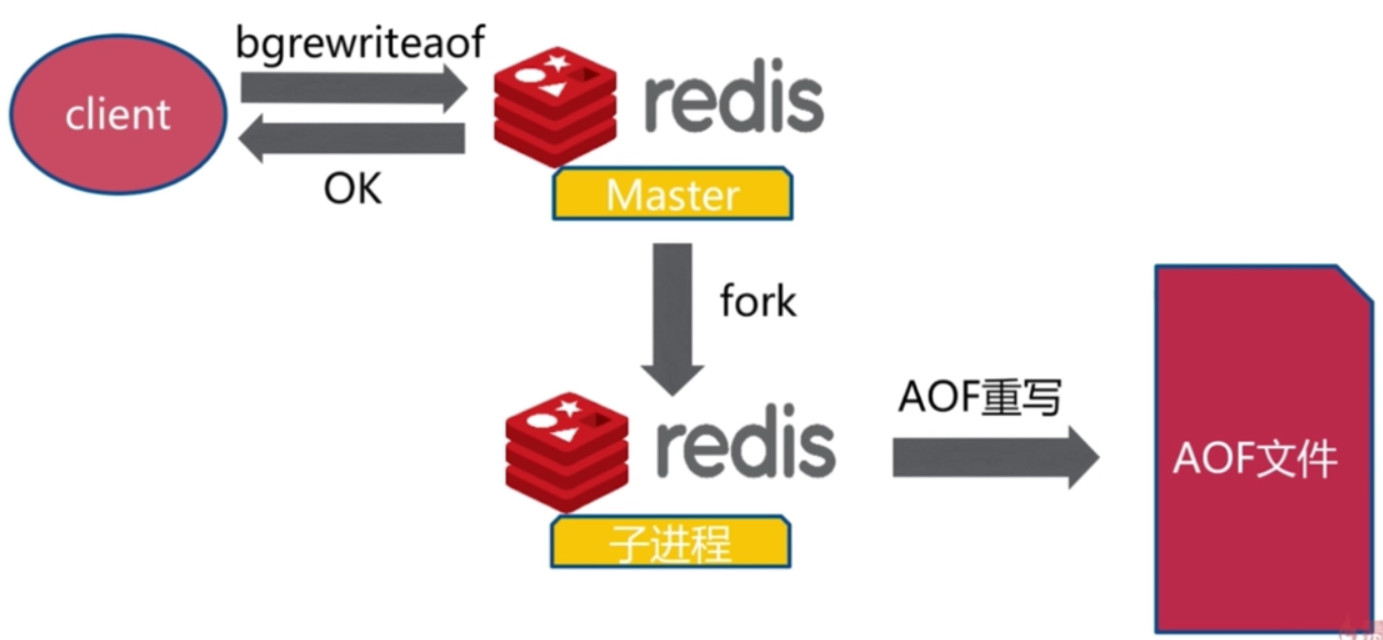
AOF重写配置
aof-load-truncatedAOF有问题时(突然宕机或其他条件造成的),在重启加载AOF文件时是否忽略这部分错误.
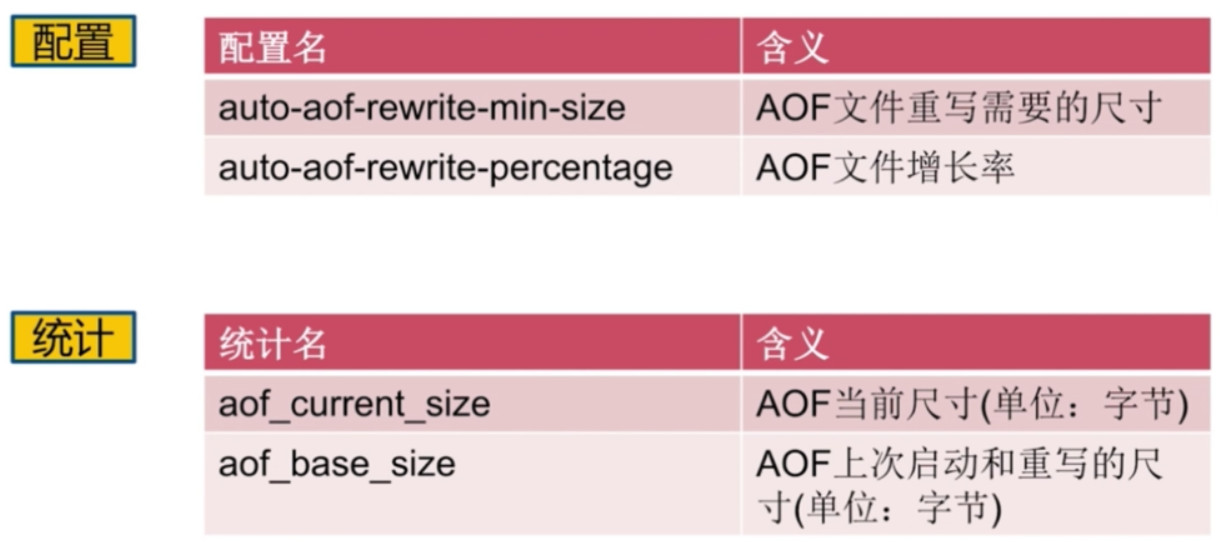
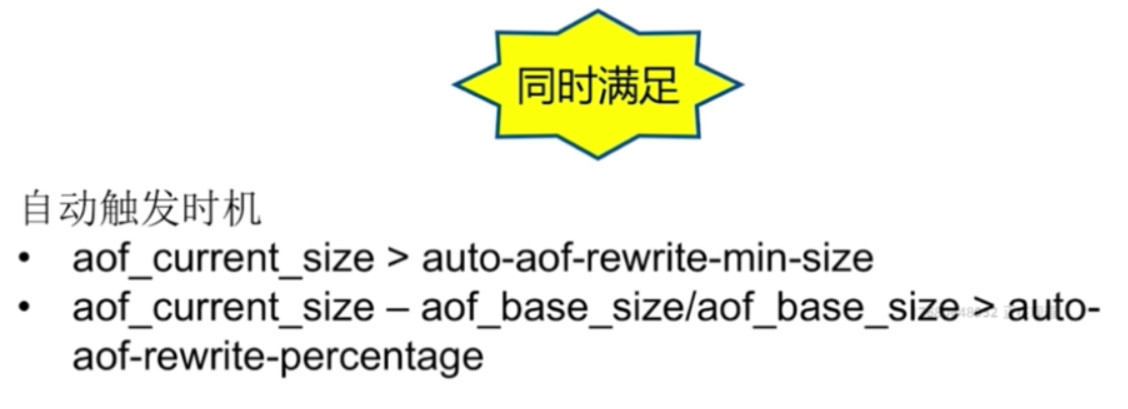
- 自动触发时机
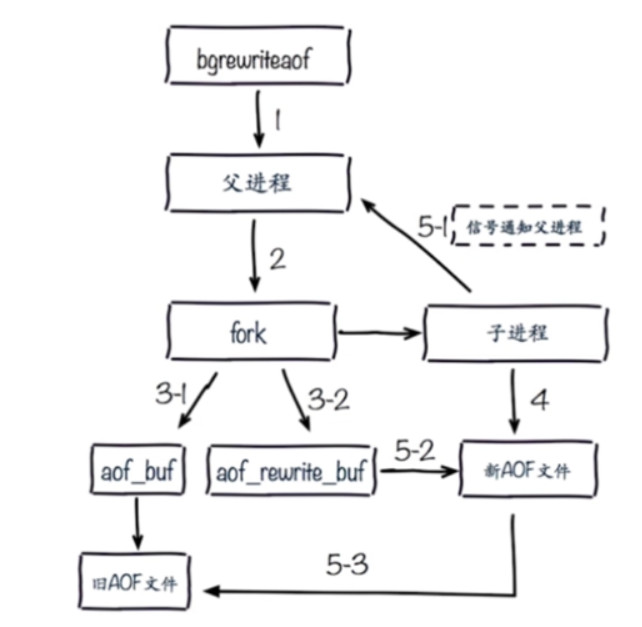
AOF重写流程
- 3-1阶段表示在执行AOF重写期间redis进行的写操作依然会通过aof_buf写入到旧的AOF文件中
- 3-2阶段表示在执行AOF重写期间redis进行的写操作还会通过aof_rewrite_buf写入到新的AOF文件中,在完成AOF文件重写后, 在5-3阶段新的AOF文件会替换掉旧的AOF文件
配置
appendonly开启AOF重写appendfilenameAOF文件名appendfsyncAOF重写策略dir生成的RDB, AOF文件及日志目录no-appendfsync-on-rewriteAOF重写时是否进行AOF的append操作, 即上图的3-1操作,(设置为no可能会在AOF重写失败时丢失AOF重写时间的这段数据, 一般为了性能设置为yes, 即不进行append操作)

RDB和AOF的抉择
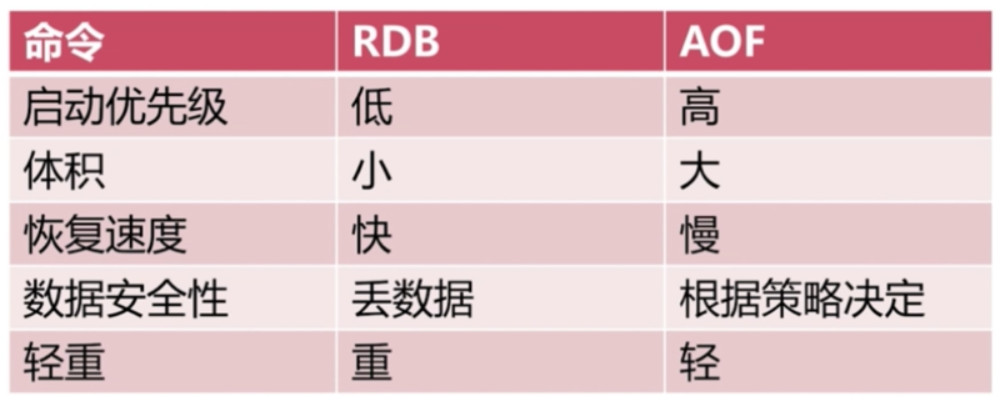
RDB与AOF
- 启动优先级: 当redis宕机后, 优先使用AOF文件进行数据恢复
- 轻重: 操作的轻重, RDB需全部数据进行持久化, 而AOF则是增量数据持久化
RDB”最佳策略”
- 关 (其实是永远关不掉的, 因为主从复制需要进行全量复制, 需要进行RDB操作)
- 集中管理 (数据备份很有作用)
- 主从, 从开 (即使是从节点, RDB操作粒度也不要设置过小)
AOF最佳策略
- 开 : 缓存和存储
- AOF重写集中管理 (fork会占用CPU, 内存, 故在进行AOF重写时要注意不要在Redis单机多部署时集中进行重写, 而要集中管理)
- everysec
最佳策略
- 小分片 使用maxmemory设置最大内存对Redis进行管理, fork, RDB传输都会产生较小的开销 (缺点是分布式情况下产生更多的redis进程, CPU可能占用更多一些)
- 缓存或者存储
- 监控 (硬盘, 内存, 负载, 网络)
- 足够的内存 (不要把全部内存分配给Redis, 否则进行fork之类的操作会造成内存错误)




