Elasticsearch篇之深入了解Search的运行机制
Search的运行机制
- Search执行的时候实际分为两个步骤运作的
- Query阶段
- Fetch阶段
- Query-Then-Fetch
Query阶段
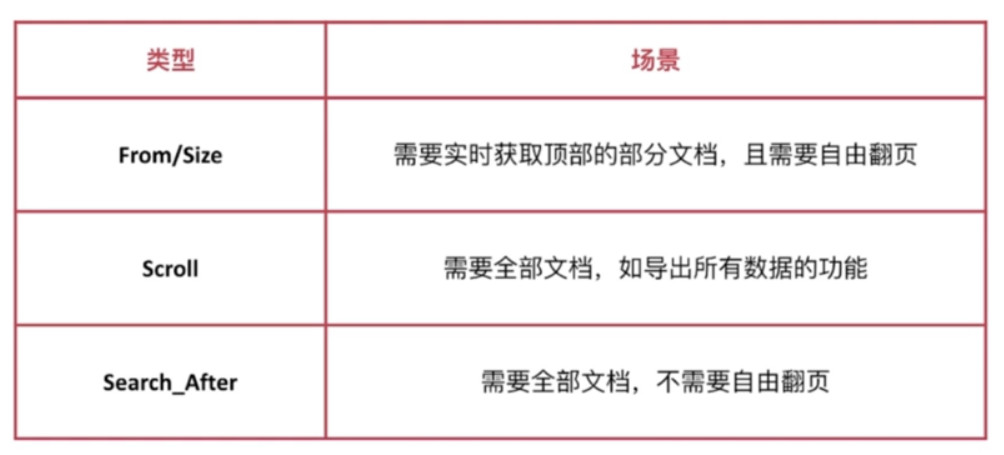
Node3在接收到用户的search请求后, 会先进行Query阶段 (此时Coordinating Node角色)
- node3在6个主副分片中随机选择3个分片, 发送search request
- 被选中的3个分片会分别执行查询并排序, 返回from + size个文档Id和排序值
- node3整合3个分片返回的from + size个文档Id, 根据排序值排序后选取
from 到 (from + size)(共size个)的文档Id
Fetch阶段
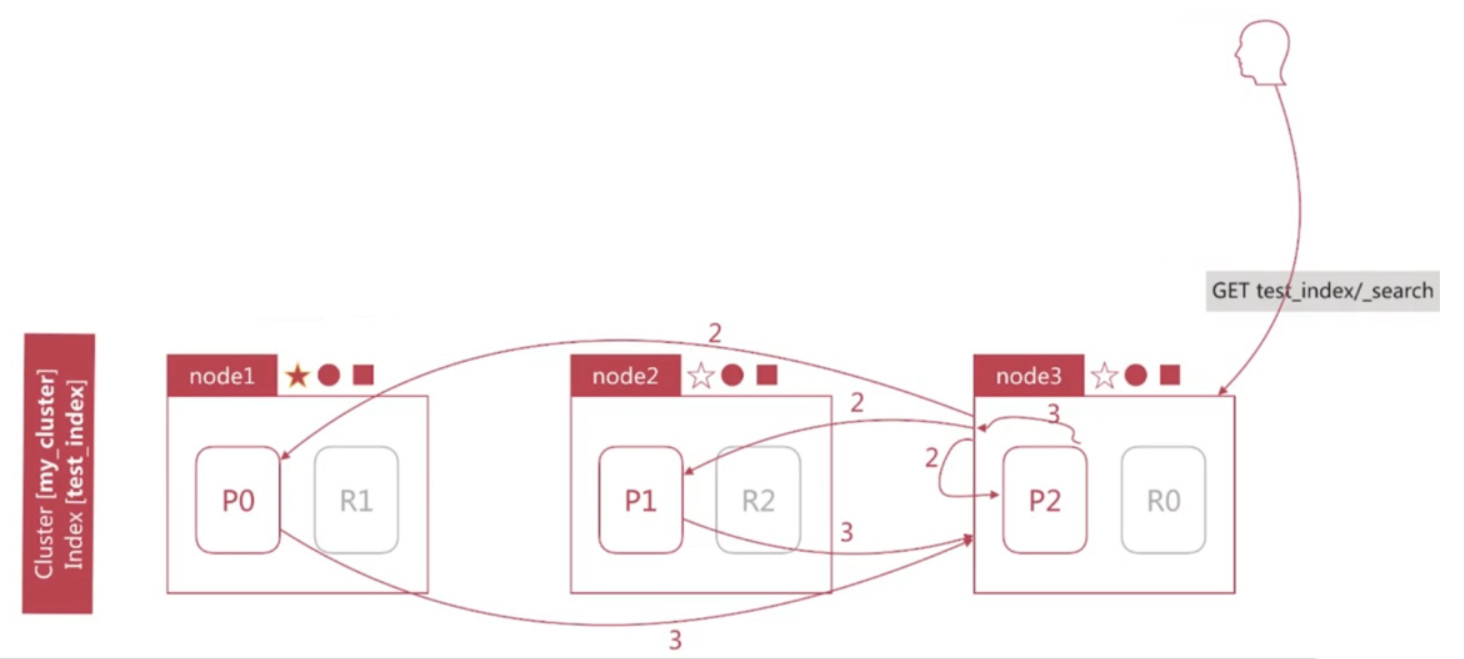
Node3根据Query阶段获取的文档Id列表去对应的shard上获取文档详情数据
- node3向相关的分片发送multi_get请求
- 3个分片返回文档详细数据
- node3拼接返回的结果并返回给客户
相关性算分问题
- 相关性算分在shard与shard之间是相互独立的, 也就意味着同一个Term的IDF等值在不同shard上是不同的.文档的相关性算分和他所处的shard相关
- 在文档数量不多时, 会导致相关性算分严重不准的情况
问题引出
首先, 在ES中插入如下文档
# request POST test_search_relevance/doc/1 { "name": "hello" } # request POST test_search_relevance/doc/2 { "name": "hello, world" } # request POST test_search_relevance/doc/3 { "name": "hello, world. a beatiful word" }查询插入的索引
test_search_relevance默认配置, 及文档插入的正确性# request GET test_search_relevance # response # "number_of_shards"值为5, 说明es默认创建的索引shard数为5 { "test_search_relevance": { "aliases": {}, "mappings": { "doc": { "properties": { "name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } }, "settings": { "index": { "creation_date": "1586624049883", "number_of_shards": "5", "number_of_replicas": "1", "uuid": "liS9BY-ERzG6hR4pezVNCw", "version": { "created": "6010199" }, "provided_name": "test_search_relevance" } } } }
request
GET test_search_relevance/_search
response
{
“took”: 19,
“timed_out”: false,
“_shards”: {
“total”: 5,
“successful”: 5,
“skipped”: 0,
“failed”: 0
},
“hits”: {
“total”: 3,
“max_score”: 1,
“hits”: [
{
“_index”: “test_search_relevance”,
“_type”: “doc”,
“_id”: “2”,
“_score”: 1,
“_source”: {
“name”: “hello, world”
}
},
{
“_index”: “test_search_relevance”,
“_type”: “doc”,
“_id”: “1”,
“_score”: 1,
“_source”: {
“name”: “hello”
}
},
{
“_index”: “test_search_relevance”,
“_type”: “doc”,
“_id”: “3”,
“_score”: 1,
“_source”: {
“name”: “hello, world. a beatiful word”
}
}
]
}
}
3. 在目标索引查询`name`字段, 查询内容为`hello`, 分析查询结果
```shell
# request
GET test_search_relevance/_search
{
"query": {
"match": {
"name": "hello"
}
}
}
# response
# 由查询结果可以看出查询的结果并非我们预期的那样(hello应该在最前面)
{
"took": 14,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.2876821,
"hits": [
{
"_index": "test_search_relevance",
"_type": "doc",
"_id": "2",
"_score": 0.2876821,
"_source": {
"name": "hello, world"
}
},
{
"_index": "test_search_relevance",
"_type": "doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "hello"
}
},
{
"_index": "test_search_relevance",
"_type": "doc",
"_id": "3",
"_score": 0.2876821,
"_source": {
"name": "hello, world. a beatiful word"
}
}
]
}
}由步骤3我们发现, 查询结果发现所有的文档得分值一样, 并非我们的预期(hello应该在最前面), 于是我们在查询字段添加
explain: true条件来查看具体的查询算分过程.# request GET test_search_relevance/_search { "explain": true, "query": { "match": { "name": "hello" } } } # response # 此时我们发现, 由于文档分散在不同的shard上("_shard"字段显示shard值), 故其直接影响到了 # docFreq的取值(此时都为1), 进而影响到了相关性算分 { "took": 27, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 0.2876821, "hits": [ { "_shard": "[test_search_relevance][2]", "_node": "95bEF7jnS0uGrVlP6cA7Dw", "_index": "test_search_relevance", "_type": "doc", "_id": "2", "_score": 0.2876821, "_source": { "name": "hello, world" }, "_explanation": { "value": 0.2876821, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.2876821, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.2876821, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 1, "description": "docFreq", "details": [] }, { "value": 1, "description": "docCount", "details": [] } ] }, { "value": 1, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2, "description": "avgFieldLength", "details": [] }, { "value": 2, "description": "fieldLength", "details": [] } ] } ] } ] } }, { "_shard": "[test_search_relevance][3]", "_node": "95bEF7jnS0uGrVlP6cA7Dw", "_index": "test_search_relevance", "_type": "doc", "_id": "1", "_score": 0.2876821, "_source": { "name": "hello" }, "_explanation": { "value": 0.2876821, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.2876821, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.2876821, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 1, "description": "docFreq", "details": [] }, { "value": 1, "description": "docCount", "details": [] } ] }, { "value": 1, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 1, "description": "avgFieldLength", "details": [] }, { "value": 1, "description": "fieldLength", "details": [] } ] } ] } ] } }, { "_shard": "[test_search_relevance][4]", "_node": "WIUsESqiTZqLs_4nQTvbeQ", "_index": "test_search_relevance", "_type": "doc", "_id": "3", "_score": 0.2876821, "_source": { "name": "hello, world. a beatiful word" }, "_explanation": { "value": 0.2876821, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.2876821, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.2876821, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 1, "description": "docFreq", "details": [] }, { "value": 1, "description": "docCount", "details": [] } ] }, { "value": 1, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 5, "description": "avgFieldLength", "details": [] }, { "value": 5, "description": "fieldLength", "details": [] } ] } ] } ] } } ] } }
解决思路
设置分片数为1个, 从根本上排除问题, 在文档数数量不多的时候可以考虑该方案, 比如百万级别到千万级别的文档.
过程:
# 1.设置分片数为1 PUT test_search_relevance { "settings": { "index": { "number_of_shards": 1 } } } # 2.插入测试数据 # request POST test_search_relevance/doc/1 { "name": "hello" } POST test_search_relevance/doc/2 { "name": "hello, world" } POST test_search_relevance/doc/3 { "name": "hello, world. a beatiful word" } # 3.查询数据 # request GET test_search_relevance/_search { "query": { "match": { "name": "hello" } } } # response { "took": 69, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 0.17940095, "hits": [ { "_index": "test_search_relevance", "_type": "doc", "_id": "1", "_score": 0.17940095, "_source": { "name": "hello" } }, { "_index": "test_search_relevance", "_type": "doc", "_id": "2", "_score": 0.14874382, "_source": { "name": "hello, world" } }, { "_index": "test_search_relevance", "_type": "doc", "_id": "3", "_score": 0.09833273, "_source": { "name": "hello, world. a beatiful word" } } ] } }由上例查询结果可以看出, 设置shard数为1可以解决相关性算分问题.
另附
explain: true查询# request GET test_search_relevance/_search { "explain": true, "query": { "match": { "name": "hello" } } } # response { "took": 8, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 0.17940095, "hits": [ { "_shard": "[test_search_relevance][0]", "_node": "95bEF7jnS0uGrVlP6cA7Dw", "_index": "test_search_relevance", "_type": "doc", "_id": "1", "_score": 0.17940095, "_source": { "name": "hello" }, "_explanation": { "value": 0.17940095, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.17940095, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.13353139, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 3, "description": "docFreq", "details": [] }, { "value": 3, "description": "docCount", "details": [] } ] }, { "value": 1.3435115, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2.6666667, "description": "avgFieldLength", "details": [] }, { "value": 1, "description": "fieldLength", "details": [] } ] } ] } ] } }, { "_shard": "[test_search_relevance][0]", "_node": "95bEF7jnS0uGrVlP6cA7Dw", "_index": "test_search_relevance", "_type": "doc", "_id": "2", "_score": 0.14874382, "_source": { "name": "hello, world" }, "_explanation": { "value": 0.14874382, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.14874382, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.13353139, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 3, "description": "docFreq", "details": [] }, { "value": 3, "description": "docCount", "details": [] } ] }, { "value": 1.113924, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2.6666667, "description": "avgFieldLength", "details": [] }, { "value": 2, "description": "fieldLength", "details": [] } ] } ] } ] } }, { "_shard": "[test_search_relevance][0]", "_node": "95bEF7jnS0uGrVlP6cA7Dw", "_index": "test_search_relevance", "_type": "doc", "_id": "3", "_score": 0.09833273, "_source": { "name": "hello, world. a beatiful word" }, "_explanation": { "value": 0.09833273, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.09833273, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.13353139, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 3, "description": "docFreq", "details": [] }, { "value": 3, "description": "docCount", "details": [] } ] }, { "value": 0.7364016, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2.6666667, "description": "avgFieldLength", "details": [] }, { "value": 5, "description": "fieldLength", "details": [] } ] } ] } ] } } ] } }
使用DFS Query-Then-Fetch
- 在不设置默认shard的情况下, 使用
dfs_query_then_fetch参数来解决此问题 - DFS Query-Then-Fetch是在拿到所有文档后再重新计算完整的计算一次相关性得分, 耗费更多的CPU和内存, 执行性能也比较低, 一般不建议使用. 使用方式如下:
# 此查询在问题引出的环境下测试(即未设置number_of_shard参数) # request GET test_search_relevance/_search?search_type=dfs_query_then_fetch { "query": { "match": { "name": "hello" } } } # response { "took": 143, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 0.17940095, "hits": [ { "_index": "test_search_relevance", "_type": "doc", "_id": "1", "_score": 0.17940095, "_source": { "name": "hello" } }, { "_index": "test_search_relevance", "_type": "doc", "_id": "2", "_score": 0.14874382, "_source": { "name": "hello, world" } }, { "_index": "test_search_relevance", "_type": "doc", "_id": "3", "_score": 0.09833273, "_source": { "name": "hello, world. a beatiful word" } } ] } }附带
explain:true的查询过程:# request GET test_search_relevance/_search?search_type=dfs_query_then_fetch { "explain": true, "query": { "match": { "name": "hello" } } } # response { "took": 42, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 3, "max_score": 0.17940095, "hits": [ { "_shard": "[test_search_relevance][3]", "_node": "95bEF7jnS0uGrVlP6cA7Dw", "_index": "test_search_relevance", "_type": "doc", "_id": "1", "_score": 0.17940095, "_source": { "name": "hello" }, "_explanation": { "value": 0.17940095, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.17940095, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.13353139, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 3, "description": "docFreq", "details": [] }, { "value": 3, "description": "docCount", "details": [] } ] }, { "value": 1.3435115, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2.6666667, "description": "avgFieldLength", "details": [] }, { "value": 1, "description": "fieldLength", "details": [] } ] } ] } ] } }, { "_shard": "[test_search_relevance][2]", "_node": "-eS9ksggR-SI6NKJRLkOeQ", "_index": "test_search_relevance", "_type": "doc", "_id": "2", "_score": 0.14874382, "_source": { "name": "hello, world" }, "_explanation": { "value": 0.14874382, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.14874382, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.13353139, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 3, "description": "docFreq", "details": [] }, { "value": 3, "description": "docCount", "details": [] } ] }, { "value": 1.113924, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2.6666667, "description": "avgFieldLength", "details": [] }, { "value": 2, "description": "fieldLength", "details": [] } ] } ] } ] } }, { "_shard": "[test_search_relevance][4]", "_node": "WIUsESqiTZqLs_4nQTvbeQ", "_index": "test_search_relevance", "_type": "doc", "_id": "3", "_score": 0.09833273, "_source": { "name": "hello, world. a beatiful word" }, "_explanation": { "value": 0.09833273, "description": "weight(name:hello in 0) [PerFieldSimilarity], result of:", "details": [ { "value": 0.09833273, "description": "score(doc=0,freq=1.0 = termFreq=1.0\n), product of:", "details": [ { "value": 0.13353139, "description": "idf, computed as log(1 + (docCount - docFreq + 0.5) / (docFreq + 0.5)) from:", "details": [ { "value": 3, "description": "docFreq", "details": [] }, { "value": 3, "description": "docCount", "details": [] } ] }, { "value": 0.7364016, "description": "tfNorm, computed as (freq * (k1 + 1)) / (freq + k1 * (1 - b + b * fieldLength / avgFieldLength)) from:", "details": [ { "value": 1, "description": "termFreq=1.0", "details": [] }, { "value": 1.2, "description": "parameter k1", "details": [] }, { "value": 0.75, "description": "parameter b", "details": [] }, { "value": 2.6666667, "description": "avgFieldLength", "details": [] }, { "value": 5, "description": "fieldLength", "details": [] } ] } ] } ] } } ] } }- 在不设置默认shard的情况下, 使用
排序
es默认会采用相关性算分排序, 用户可以通过设定sorting参数来自行设定排序规则

按照多个字段排序
GET /test_search_index/_search
{ “sort”: [{ "birth": { "order": "desc" }, "_score": { "order": "desc" }, "_doc": { "order": "desc" } }]
}示例1:
使用的数据
POST test_search_index/doc/_bulk {"index":{"_id":"1"}} {"username":"alfred way","job":"java engineer","age":18,"birth":"1990-01-02","isMarried":false} {"index":{"_id":"2"}} {"username":"alfred","job":"java senior engineer and java specialist","age":28,"birth":"1980-05-07","isMarried":true} {"index":{"_id":"3"}} {"username":"lee","job":"java and ruby engineer","age":22,"birth":"1985-08-07","isMarried":false} {"index":{"_id":"4"}} {"username":"alfred junior way","job":"ruby engineer","age":23,"birth":"1989-08-07","isMarried":false}# request GET /test_search_index/_search { "sort": [ { "birth": { "order": "desc" } } ] } # response # 在使用sort排序时, 默认的按照相关性算分排序就失效了, 故该查询没有计算文档的相关性得分 # "_score": null { "took": 405, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": null, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "1", "_score": null, "_source": { "username": "alfred way", "job": "java engineer", "age": 18, "birth": "1990-01-02", "isMarried": false }, "sort": [ 631238400000 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "4", "_score": null, "_source": { "username": "alfred junior way", "job": "ruby engineer", "age": 23, "birth": "1989-08-07", "isMarried": false }, "sort": [ 618451200000 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "3", "_score": null, "_source": { "username": "lee", "job": "java and ruby engineer", "age": 22, "birth": "1985-08-07", "isMarried": false }, "sort": [ 492220800000 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "2", "_score": null, "_source": { "username": "alfred", "job": "java senior engineer and java specialist", "age": 28, "birth": "1980-05-07", "isMarried": true }, "sort": [ 326505600000 ] } ] } }示例2:
# request GET /test_search_index/_search { "sort": [ { "birth": { "order": "desc" }, "_score": { "order": "desc" }, "_doc": { "order": "desc" } } ] } # response # 由于此排序用到了_score字段, 故es对其文档进行了相关性算分 { "took": 72, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": null, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "1", "_score": 1, "_source": { "username": "alfred way", "job": "java engineer", "age": 18, "birth": "1990-01-02", "isMarried": false }, "sort": [ 631238400000, 1, 0 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "4", "_score": 1, "_source": { "username": "alfred junior way", "job": "ruby engineer", "age": 23, "birth": "1989-08-07", "isMarried": false }, "sort": [ 618451200000, 1, 1 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "3", "_score": 1, "_source": { "username": "lee", "job": "java and ruby engineer", "age": 22, "birth": "1985-08-07", "isMarried": false }, "sort": [ 492220800000, 1, 0 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "2", "_score": 1, "_source": { "username": "alfred", "job": "java senior engineer and java specialist", "age": 28, "birth": "1980-05-07", "isMarried": true }, "sort": [ 326505600000, 1, 0 ] } ] } }
字符串排序
按照字符串排序比较特殊, 因为es有text 和keyword两种类型, 针对text类型排序, 如下所示:

排序过程
排序的过程实质是对字段原始内容排序的过程, 这个过程中倒排索引无法发挥作用, 需要用到正排索引, 也就是通过文档Id和字段可以快速得到字段原始内容.
es对此提供了2种实现方式:
- fielddata (默认禁用)
- doc values (默认启用, 且对text类型无效)

Fielddata
fielddata默认是关闭的, 可以通过如下api开启:
- 此时字符串是按照分词后的term排序, 往往结果很难符合预期
- 一般是在对分词做聚合分析的时候开启

演示(注意执行流程):
# 1.request GET /test_search_index/_search { "sort": [ { "username": { "order": "desc" } } ] } # 2.request GET /test_search_index/_search { "sort": [ { "username": { "order": "desc" } } ] } # 2.response { "error": { "root_cause": [ { "type": "illegal_argument_exception", "reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [username] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead." } ], "type": "search_phase_execution_exception", "reason": "all shards failed", "phase": "query", "grouped": true, "failed_shards": [ { "shard": 0, "index": "test_search_index", "node": "95bEF7jnS0uGrVlP6cA7Dw", "reason": { "type": "illegal_argument_exception", "reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [username] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead." } } ] }, "status": 400 } # 3.request PUT /test_search_index/_mapping/doc { "properties": { "username": { "type": "text", "fielddata": true } } } # 4.request GET /test_search_index/_search { "sort": [ { "username": { "order": "desc" } } ] } # 4.response { "took": 53, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": null, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "4", "_score": null, "_source": { "username": "alfred junior way", "job": "ruby engineer", "age": 23, "birth": "1989-08-07", "isMarried": false }, "sort": [ "way" ] }, { "_index": "test_search_index", "_type": "doc", "_id": "1", "_score": null, "_source": { "username": "alfred way", "job": "java engineer", "age": 18, "birth": "1990-01-02", "isMarried": false }, "sort": [ "way" ] }, { "_index": "test_search_index", "_type": "doc", "_id": "3", "_score": null, "_source": { "username": "lee", "job": "java and ruby engineer", "age": 22, "birth": "1985-08-07", "isMarried": false }, "sort": [ "lee" ] }, { "_index": "test_search_index", "_type": "doc", "_id": "2", "_score": null, "_source": { "username": "alfred", "job": "java senior engineer and java specialist", "age": 28, "birth": "1980-05-07", "isMarried": true }, "sort": [ "alfred" ] } ] } }
Doc Values
Doc Values默认是启用的, 可以在创建索引的时候关闭
- 如果后面要再开启doc values, 需要reindex操作

docvalues_fields
可以通过该字段获取fielddata或者doc values中储存的内容

示例:
# request PUT /test_search_index/_mapping/doc { "properties": { "username": { "type": "text", "fielddata": false } } } # request GET /test_search_index/_search { "docvalue_fields": [ "username", "birth", "age" ] } # response { "took": 15, "timed_out": false, "_shards": { "total": 5, "successful": 2, "skipped": 0, "failed": 3, "failures": [ { "shard": 2, "index": "test_search_index", "node": "WIUsESqiTZqLs_4nQTvbeQ", "reason": { "type": "illegal_argument_exception", "reason": "Fielddata is disabled on text fields by default. Set fielddata=true on [username] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead." } } ] }, "hits": { "total": 4, "max_score": 1, "hits": [] } } # request PUT /test_search_index/_mapping/doc { "properties": { "username": { "type": "text", "fielddata": true } } } # request GET /test_search_index/_search { "docvalue_fields": [ "username", "birth", "age" ] } # response { "took": 48, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": 1, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "2", "_score": 1, "_source": { "username": "alfred", "job": "java senior engineer and java specialist", "age": 28, "birth": "1980-05-07", "isMarried": true }, "fields": { "birth": [ "1980-05-07T00:00:00.000Z" ], "age": [ 28 ], "username": [ "alfred" ] } }, { "_index": "test_search_index", "_type": "doc", "_id": "4", "_score": 1, "_source": { "username": "alfred junior way", "job": "ruby engineer", "age": 23, "birth": "1989-08-07", "isMarried": false }, "fields": { "birth": [ "1989-08-07T00:00:00.000Z" ], "age": [ 23 ], "username": [ "alfred", "junior", "way" ] } }, { "_index": "test_search_index", "_type": "doc", "_id": "1", "_score": 1, "_source": { "username": "alfred way", "job": "java engineer", "age": 18, "birth": "1990-01-02", "isMarried": false }, "fields": { "birth": [ "1990-01-02T00:00:00.000Z" ], "age": [ 18 ], "username": [ "alfred", "way" ] } }, { "_index": "test_search_index", "_type": "doc", "_id": "3", "_score": 1, "_source": { "username": "lee", "job": "java and ruby engineer", "age": 22, "birth": "1985-08-07", "isMarried": false }, "fields": { "birth": [ "1985-08-07T00:00:00.000Z" ], "age": [ 22 ], "username": [ "lee" ] } } ] } }
分页与遍历
- es提供了3种方式来解决分页与遍历的问题
- from/size
- scroll
- search_after
From/Size
最常用的分页方案
- from指明开始位置
- size指明获取总数

深度分页
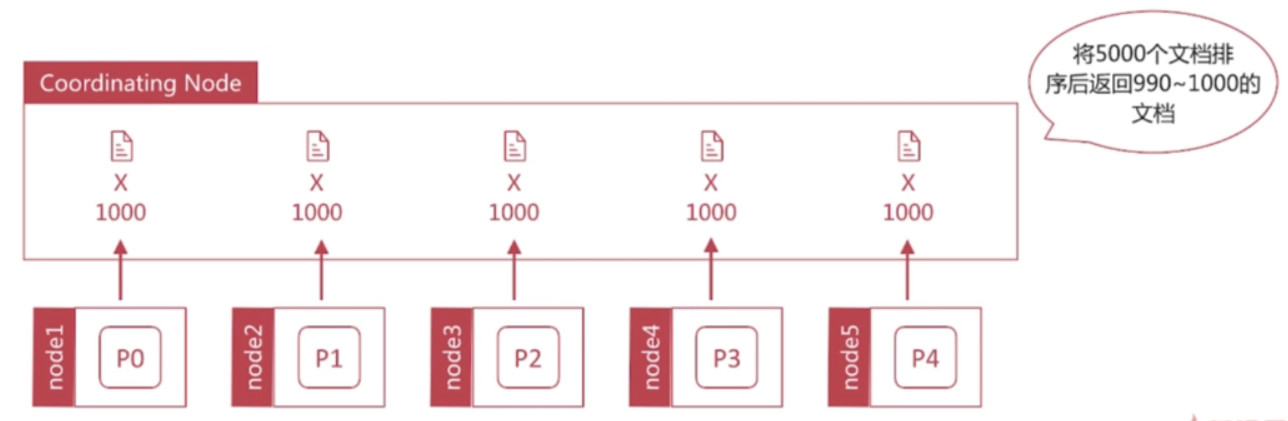
深度分页是一个经典的问题: 在数据分片存储的情况下如何获取前1000个文档?
- 获取从990~1000的文档时, 会在每个分片上都先获取1000个文档, 然后由Coordinating Node聚合所有的分片的结果再排序选取前1000个文档.
- 页数越深, 处理文档越多, 占用内存越多, 耗时越长. 尽量避免深度分页, es通过index.max_result_window限定最多到10000条数据
# request
GET /test_search_index/_search
{
"from": 2,
"size": 2
}
# response
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "3",
"_score": 1,
"_source": {
"username": "lee",
"job": "java and ruby engineer",
"age": 22,
"birth": "1985-08-07",
"isMarried": false
}
}
]
}
}# request
GET /test_search_index/_search
{
"from": 10000,
"size": 2
}
# response
{
"error": {
"root_cause": [
{
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10002]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "test_search_index",
"node": "95bEF7jnS0uGrVlP6cA7Dw",
"reason": {
"type": "query_phase_execution_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10002]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
]
},
"status": 500
}Scroll
遍历文档集的api, 以快照的方式来避免深度分页的问题
- 不能用来做实时搜索, 因为数据不是实时的
- 尽量不要使用复杂的sort条件, 使用_doc最高效
- 使用稍显复杂
使用示例
- 第一步需要发起一个scroll search, 如下所示:
- es在收到该请求后会根据查询条件创建文档Id合集的快照
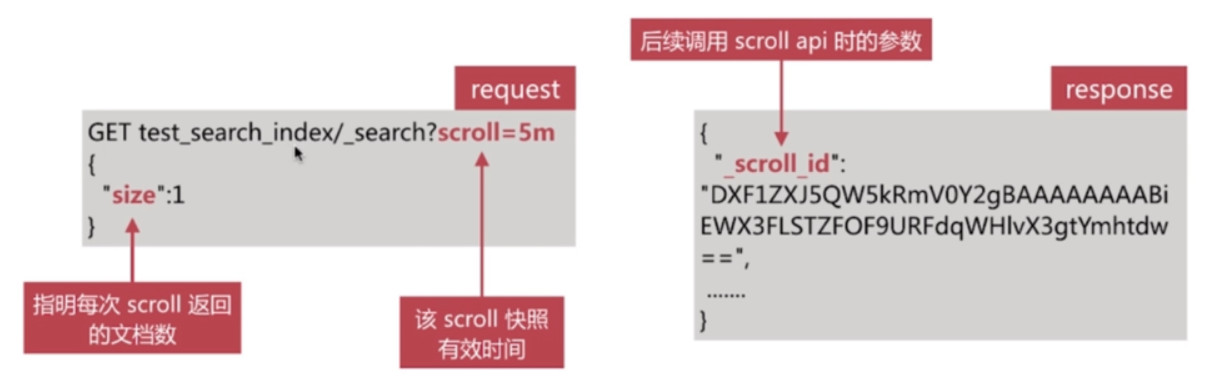
第二步调用scroll search的api, 获取文档集合, 如下所示:
- 不断迭代调用直到hits.hits数组为空时停止

演示示例:
# request GET /test_search_index/_search?scroll=5m { "size": 2 } # response { "_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAA_FldJVXNFU3FpVFpxTHNfNG5RVHZiZVEAAAAAAAAAPhY5NWJFRjdqblMwdUdyVmxQNmNBN0R3AAAAAAAAAD0WV0lVc0VTcWlUWnFMc180blFUdmJlUQAAAAAAAAA4Fi1lUzlrc2dnUi1TSTZOS0pSTGtPZVEAAAAAAAAAPhZXSVVzRVNxaVRacUxzXzRuUVR2YmVR", "took": 12, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": 1, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "2", "_score": 1, "_source": { "username": "alfred", "job": "java senior engineer and java specialist", "age": 28, "birth": "1980-05-07", "isMarried": true } }, { "_index": "test_search_index", "_type": "doc", "_id": "4", "_score": 1, "_source": { "username": "alfred junior way", "job": "ruby engineer", "age": 23, "birth": "1989-08-07", "isMarried": false } } ] } } # request POST _search/scroll { "scroll": "5m", "scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAA_FldJVXNFU3FpVFpxTHNfNG5RVHZiZVEAAAAAAAAAPhY5NWJFRjdqblMwdUdyVmxQNmNBN0R3AAAAAAAAAD0WV0lVc0VTcWlUWnFMc180blFUdmJlUQAAAAAAAAA4Fi1lUzlrc2dnUi1TSTZOS0pSTGtPZVEAAAAAAAAAPhZXSVVzRVNxaVRacUxzXzRuUVR2YmVR" } # response { "_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAA_FldJVXNFU3FpVFpxTHNfNG5RVHZiZVEAAAAAAAAAPhY5NWJFRjdqblMwdUdyVmxQNmNBN0R3AAAAAAAAAD0WV0lVc0VTcWlUWnFMc180blFUdmJlUQAAAAAAAAA4Fi1lUzlrc2dnUi1TSTZOS0pSTGtPZVEAAAAAAAAAPhZXSVVzRVNxaVRacUxzXzRuUVR2YmVR", "took": 13, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": 1, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "1", "_score": 1, "_source": { "username": "alfred way", "job": "java engineer", "age": 18, "birth": "1990-01-02", "isMarried": false } }, { "_index": "test_search_index", "_type": "doc", "_id": "3", "_score": 1, "_source": { "username": "lee", "job": "java and ruby engineer", "age": 22, "birth": "1985-08-07", "isMarried": false } } ] } } # request POST _search/scroll { "scroll": "5m", "scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAA_FldJVXNFU3FpVFpxTHNfNG5RVHZiZVEAAAAAAAAAPhY5NWJFRjdqblMwdUdyVmxQNmNBN0R3AAAAAAAAAD0WV0lVc0VTcWlUWnFMc180blFUdmJlUQAAAAAAAAA4Fi1lUzlrc2dnUi1TSTZOS0pSTGtPZVEAAAAAAAAAPhZXSVVzRVNxaVRacUxzXzRuUVR2YmVR" } # response { "_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAAAA_FldJVXNFU3FpVFpxTHNfNG5RVHZiZVEAAAAAAAAAPhY5NWJFRjdqblMwdUdyVmxQNmNBN0R3AAAAAAAAAD0WV0lVc0VTcWlUWnFMc180blFUdmJlUQAAAAAAAAA4Fi1lUzlrc2dnUi1TSTZOS0pSTGtPZVEAAAAAAAAAPhZXSVVzRVNxaVRacUxzXzRuUVR2YmVR", "took": 6, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": 1, "hits": [] } }- 第一步需要发起一个scroll search, 如下所示:
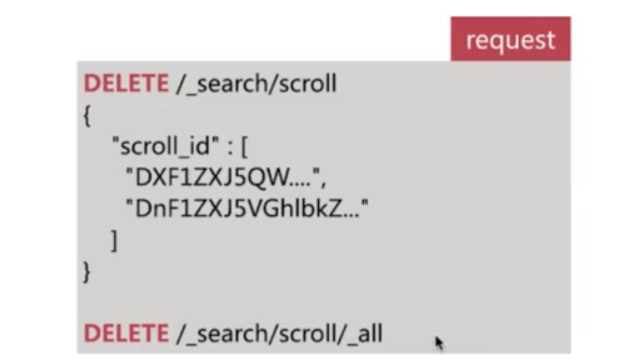
过多的scroll调用会占用大量的内存, 可以通过clear api删除过多的scroll快照:
Search_After
避免了深度分页的性能问题, 提供实时的下一页文档获取功能
- 缺点是不能使用from参数, 即不能指定页数
- 只能下一页, 不能上一页
- 使用简单
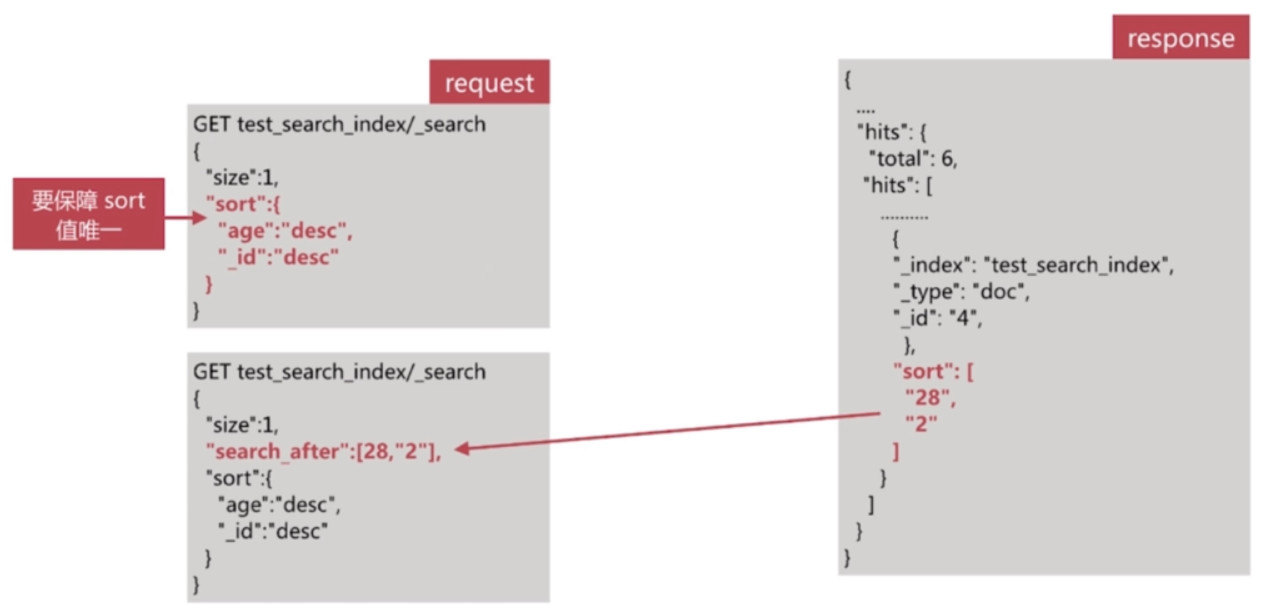
使用步骤
- 第一步为正常的搜索, 但要指定sort值, 并保证值唯一
- 第二步为使用上一步最后一个文档的sort值进行查询
演示:
# request GET /test_search_index/_search { "size": 2, "sort": [ { "age": { "order": "desc" } }, { "birth": { "order": "desc" } } ] } # response { "took": 6, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": null, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "2", "_score": null, "_source": { "username": "alfred", "job": "java senior engineer and java specialist", "age": 28, "birth": "1980-05-07", "isMarried": true }, "sort": [ 28, 326505600000 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "4", "_score": null, "_source": { "username": "alfred junior way", "job": "ruby engineer", "age": 23, "birth": "1989-08-07", "isMarried": false }, "sort": [ 23, 618451200000 ] } ] } } # request GET /test_search_index/_search { "size": 2, "search_after": [ 23, 618451200000 ], "sort": [ { "age": { "order": "desc" } }, { "birth": { "order": "desc" } } ] } # response { "took": 12, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": null, "hits": [ { "_index": "test_search_index", "_type": "doc", "_id": "3", "_score": null, "_source": { "username": "lee", "job": "java and ruby engineer", "age": 22, "birth": "1985-08-07", "isMarried": false }, "sort": [ 22, 492220800000 ] }, { "_index": "test_search_index", "_type": "doc", "_id": "1", "_score": null, "_source": { "username": "alfred way", "job": "java engineer", "age": 18, "birth": "1990-01-02", "isMarried": false }, "sort": [ 18, 631238400000 ] } ] } } # request GET /test_search_index/_search { "size": 2, "search_after": [ 18, 631238400000 ], "sort": [ { "age": { "order": "desc" } }, { "birth": { "order": "desc" } } ] } # response { "took": 5, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": 4, "max_score": null, "hits": [] } }如何避免深度分页问题?
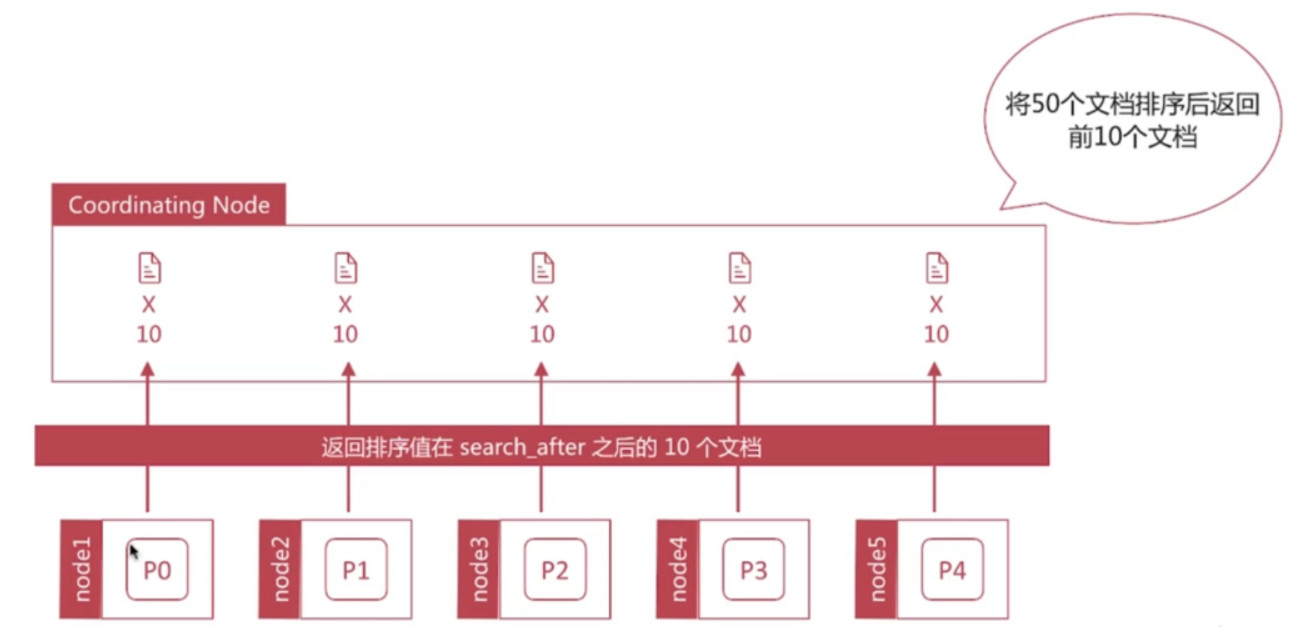
- 通过唯一排序值定位将每次要处理的文档数都控制在size范围内
应用场景