Elasticsearch篇之Search API
Search API概览
实现对es中储存的数据进行查询分析, endpoint为
_search, 如下所示:
查询主要有两种形式
- URI Search
- 操作简便, 方便通过命令行测试
- 仅包含部分查询语法
- Request Body Search
- es提供的完备查询语法 Query DSL (Domain Specific language)

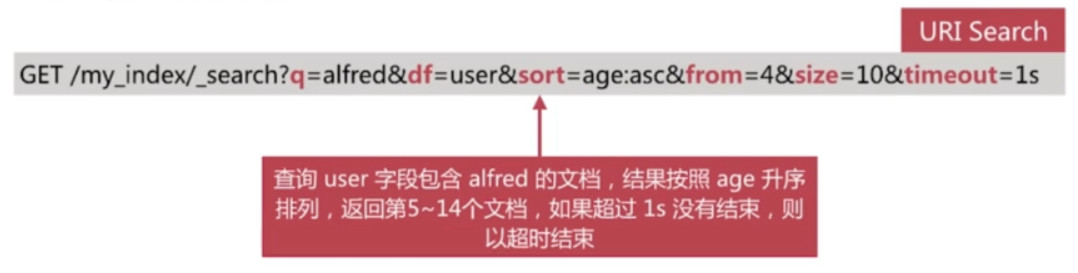
- URI Search
URI Search
通过url query 参数来实现搜索, 常用参数如下:
- q 指定查询的语句, 语法为Query String Syntax
- df q中不指定字段时默认查询的字段, 如果不指定, es会查询所有字段
- sort 排序
- timeout 指定超时时间, 默认不超时
- from, size 用于分页
Query String Syntax
term 与 phrase
- term(做分词处理): alfred way等效于 alfred OR way
- phrase(不做分词处理): “alfred way” 词语查询, 要求先后顺序
泛查询
该查询q参数没有指定字段, 且df参数没有指定字段
alfred 等效于在所有字段去匹配该term
指定字段
- 示例 name: alfred
Group分组
使用括号指定匹配的规则
示例 (quick OR brown) AND fox
示例 status: (active OR pending) title: (full text search)
布尔操作符
- AND(&&), OR(||), NOT(!)
- 示例 name: (tom NOT lee)
- 注意大写, 不能小写
+,-分别对应must 和 must_not- 示例 name: (tom +lee -alfred)
- 示例 name:((lee && !alfred) || (tom && lee && !alfred))
+在url中会被解析为空格, 要使用encode 后的结果才可以, 为%2B
范围查询
支持数值和日期
区间写法, 闭区间用[], 开区间用{}
- 示例 age:[1 TO 10] 意为 1 <= age <= 10
- 示例 age:[1 TO 10} 意为 1 <= age < 10
- 示例 age:[1 TO] 意为 1 <= age
- 示例 age:[* TO 10] 意为 age <= 10
算术符号写法
- 示例 age: >= 1
- 示例 age: (>= 1 && <= 10) 或者 age: (+>= 1 +<= 10)
通配符查询
?代表1个字符,*代表0或多个字符示例 name: t?m
示例 name: tom*
示例 name: t*m
通配符匹配执行效率低, 且占用内存较多, 不建议使用
如无特殊要求, 不要将
?或者*放在最前面
正则表达式匹配
- 示例 name: /[mb]oat/
模糊匹配(fuzzy query)
- 示例 name: roam~1
- 匹配与roam 差一个character的词, 比如foam, roams等
近似度查询(proximity search)
- “fox quick”~2
- 以term为单位进行差异比较, 比如 “quick fox” “quick brown fox”都会被匹配
查询示例:
# 测试Query String Syntax
# 测试数据
POST test_search_index/doc/_bulk
{"index":{"_id":"1"}}
{"username":"alfred way","job":"java engineer","age":18,"birth":"1990-01-02","isMarried":false}
{"index":{"_id":"2"}}
{"username":"alfred","job":"java senior engineer and java specialist","age":28,"birth":"1980-05-07","isMarried":true}
{"index":{"_id":"3"}}
{"username":"lee","job":"java and ruby engineer","age":22,"birth":"1985-08-07","isMarried":false}
{"index":{"_id":"4"}}
{"username":"alfred junior way","job":"ruby engineer","age":23,"birth":"1989-08-07","isMarried":false}
# 1.request
# 测试q参数
# 查询所有字段有包含alfred的文档
GET /test_search_index/_search?q=alfred
# 1.response
{
"took": 78,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.6931472,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "2",
"_score": 0.6931472,
"_source": {
"username": "alfred",
"job": "java senior engineer and java specialist",
"age": 28,
"birth": "1980-05-07",
"isMarried": true
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "4",
"_score": 0.1513613,
"_source": {
"username": "alfred junior way",
"job": "ruby engineer",
"age": 23,
"birth": "1989-08-07",
"isMarried": false
}
}
]
}
}
# 2.request
# 使用profile设置可以查看es查询的详细过程
# 测试profile的用法
GET /test_search_index/_search?q=alfred
{
"profile": true
}
# 2.response
{
"took": 66,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 0.6931472,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "2",
"_score": 0.6931472,
"_source": {
"username": "alfred",
"job": "java senior engineer and java specialist",
"age": 28,
"birth": "1980-05-07",
"isMarried": true
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "4",
"_score": 0.1513613,
"_source": {
"username": "alfred junior way",
"job": "ruby engineer",
"age": 23,
"birth": "1989-08-07",
"isMarried": false
}
}
]
},
"profile": {
"shards": [
{
"id": "[Eyro1LLhQOSsyBQNJV86kQ][test_search_index][0]",
"searches": [
{
"query": [
{
"type": "DisjunctionMaxQuery",
"description": """(username.keyword:alfred | MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]") | job:alfred | MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]") | username:alfred | job.keyword:alfred)""",
"time_in_nanos": 474000,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 473999,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "username.keyword:alfred",
"time_in_nanos": 59956,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 59955,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]")""",
"time_in_nanos": 1858,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 1857,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job:alfred",
"time_in_nanos": 35355,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 35354,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]")""",
"time_in_nanos": 740,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 739,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "username:alfred",
"time_in_nanos": 27501,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 27500,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job.keyword:alfred",
"time_in_nanos": 26546,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 26545,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 17661,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": 10467,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 1881
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[Eyro1LLhQOSsyBQNJV86kQ][test_search_index][1]",
"searches": [
{
"query": [
{
"type": "DisjunctionMaxQuery",
"description": """(username.keyword:alfred | MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]") | job:alfred | MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]") | username:alfred | job.keyword:alfred)""",
"time_in_nanos": 159743,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 159742,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "username.keyword:alfred",
"time_in_nanos": 45517,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 45516,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]")""",
"time_in_nanos": 9510,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 9509,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job:alfred",
"time_in_nanos": 25277,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 25276,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]")""",
"time_in_nanos": 646,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 645,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "username:alfred",
"time_in_nanos": 24136,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 24135,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job.keyword:alfred",
"time_in_nanos": 20368,
"breakdown": {
"score": 0,
"build_scorer_count": 0,
"match_count": 0,
"create_weight": 20367,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 0,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 8905,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": 1153,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 437
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[Eyro1LLhQOSsyBQNJV86kQ][test_search_index][2]",
"searches": [
{
"query": [
{
"type": "DisjunctionMaxQuery",
"description": """(username.keyword:alfred | MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]") | job:alfred | MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]") | username:alfred | job.keyword:alfred)""",
"time_in_nanos": 1616489,
"breakdown": {
"score": 16996,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 315929,
"next_doc": 14935,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 3,
"score_count": 2,
"build_scorer": 1268621,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "username.keyword:alfred",
"time_in_nanos": 751330,
"breakdown": {
"score": 3394,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 123268,
"next_doc": 3196,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 621466,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]")""",
"time_in_nanos": 6639,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 5702,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 935,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job:alfred",
"time_in_nanos": 51639,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 49299,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 2338,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]")""",
"time_in_nanos": 1127,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 822,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 303,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "username:alfred",
"time_in_nanos": 125399,
"breakdown": {
"score": 7989,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 48097,
"next_doc": 3758,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 3,
"score_count": 2,
"build_scorer": 65547,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job.keyword:alfred",
"time_in_nanos": 49838,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 48713,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 1123,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 16905,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": 10222469,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 30953
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[Eyro1LLhQOSsyBQNJV86kQ][test_search_index][3]",
"searches": [
{
"query": [
{
"type": "DisjunctionMaxQuery",
"description": """(username.keyword:alfred | MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]") | job:alfred | MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]") | username:alfred | job.keyword:alfred)""",
"time_in_nanos": 376655,
"breakdown": {
"score": 2945,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 267481,
"next_doc": 3414,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 102809,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "username.keyword:alfred",
"time_in_nanos": 94069,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 90252,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 3815,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]")""",
"time_in_nanos": 2120,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 1067,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 1051,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job:alfred",
"time_in_nanos": 45978,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 45406,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 570,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]")""",
"time_in_nanos": 1291,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 816,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 473,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "username:alfred",
"time_in_nanos": 128922,
"breakdown": {
"score": 2326,
"build_scorer_count": 2,
"match_count": 0,
"create_weight": 50312,
"next_doc": 2021,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 2,
"score_count": 1,
"build_scorer": 74257,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job.keyword:alfred",
"time_in_nanos": 43668,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 42613,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 1053,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 7191,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": 9782718,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 9198
}
]
}
]
}
],
"aggregations": []
},
{
"id": "[Eyro1LLhQOSsyBQNJV86kQ][test_search_index][4]",
"searches": [
{
"query": [
{
"type": "DisjunctionMaxQuery",
"description": """(username.keyword:alfred | MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]") | job:alfred | MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]") | username:alfred | job.keyword:alfred)""",
"time_in_nanos": 360917,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 344405,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 16510,
"advance": 0,
"advance_count": 0
},
"children": [
{
"type": "TermQuery",
"description": "username.keyword:alfred",
"time_in_nanos": 89067,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 85608,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 3457,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [birth] query, caused by parse_exception:[failed to parse date field [alfred] with format [strict_date_optional_time||epoch_millis]]")""",
"time_in_nanos": 1710,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 1002,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 706,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job:alfred",
"time_in_nanos": 122999,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 122410,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 587,
"advance": 0,
"advance_count": 0
}
},
{
"type": "MatchNoDocsQuery",
"description": """MatchNoDocsQuery("failed [age] query, caused by number_format_exception:[For input string: "alfred"]")""",
"time_in_nanos": 1352,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 1038,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 312,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "username:alfred",
"time_in_nanos": 53253,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 52748,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 503,
"advance": 0,
"advance_count": 0
}
},
{
"type": "TermQuery",
"description": "job.keyword:alfred",
"time_in_nanos": 42649,
"breakdown": {
"score": 0,
"build_scorer_count": 1,
"match_count": 0,
"create_weight": 42028,
"next_doc": 0,
"match": 0,
"create_weight_count": 1,
"next_doc_count": 0,
"score_count": 0,
"build_scorer": 619,
"advance": 0,
"advance_count": 0
}
}
]
}
],
"rewrite_time": 7234,
"collector": [
{
"name": "CancellableCollector",
"reason": "search_cancelled",
"time_in_nanos": 4641913,
"children": [
{
"name": "SimpleTopScoreDocCollector",
"reason": "search_top_hits",
"time_in_nanos": 1527
}
]
}
]
}
],
"aggregations": []
}
]
}
}
# 3.request
# 测试指定字段查询
# 查询username字段包含way的文档
GET /test_search_index/_search?q=username:way
# 3.response
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.5754429,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "4",
"_score": 0.5754429,
"_source": {
"username": "alfred junior way",
"job": "ruby engineer",
"age": 23,
"birth": "1989-08-07",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.2876821,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
}
]
}
}
# 4.request
# 测试phrase查询
# 注意以下两个的区别:
# 1) 查询username字段包含alfred的, 或者其他所有字段包含way的文档
# 2) 查询username字段包含alfred way的(alfred way是一个整体)文档
GET /test_search_index/_search?q=username:alfred way
GET /test_search_index/_search?q=username:"alfred way"
# 4.response
{
"took": 11,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.5753642,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
}
]
}
}
# 5.request
# 测试布尔操作符
# 查询username字段包含alfred且不包含way的文档
GET /test_search_index/_search?q=username: (alfred NOT way)
# 查询username字段包含alfred且必须包含way的文档
GET /test_search_index/_search?q=username: (alfred %2Bway)
# 6.request
# 测试范围查询, 支持数值和日期
# 查询age字段>25, 注意>于数字之间不能有空格
GET /test_search_index/_search?q=age: >25
# 查询birth字段>1986且<1990
GET /test_search_index/_search?q=birth: (>1986 AND <1990)Request Body Search
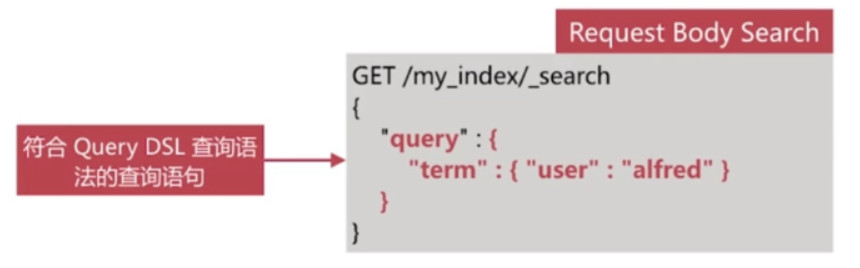
将查询语句通过http request body 发送到es, 主要包含如下参数:
- query 符合 Query DSL语法的查询语句
- from, size
- timeout
- sort
- ……
Query DSL
- 基于Json定义的查询语言, 主要包含如下两种类型:
- 字段类查询
- 如term, match, range等, 只针对某一个字段进行查询
- 复合查询
- 如bool查询等, 包含一个或多个字段类查询或者复合查询
- 字段类查询
字段类查询
- 字段类查询主要包括以下两类:
- 全文匹配
- 针对text类型的字段进行全文检索, 会对查询的语句先进行分词处理
- 如match, match_phrase等query类型
- 单词匹配
- 不会对查询语句进行分词处理, 直接去匹配字段的倒排索引
- 如term, terms, range 等query类型
- 全文匹配
Match Query
- 对字段进行全文检索, 最基本和常用的查询类型, API示例如下:


Match Query 检索流程
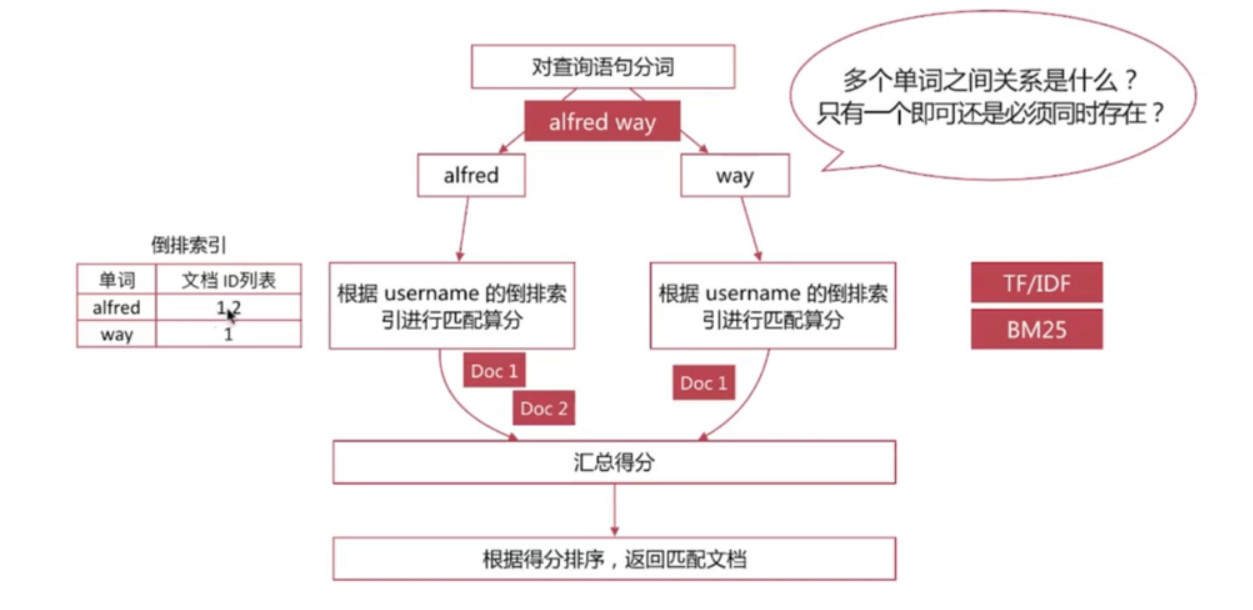
通过operator参数可以控制单词间的匹配关系, 可选项为
or和and如下示例: 查询username字段包含alfred且包含way的文档

minimum_should_match 参数可以控制需要匹配的单词数
如下示例: 查询username字段包含alfred, way(query中的查询所有分词)中两个单词的文档

相关性算分
相关性算分是指文档与查询语句间的相关度, 英文为relevance
通过倒排索引可以获取与查询语句相匹配的文档列表, 那么如何将最符合用户查询需求的文档放在最前列呢?
本质是一个排序问题, 排序的依据是相关性算分
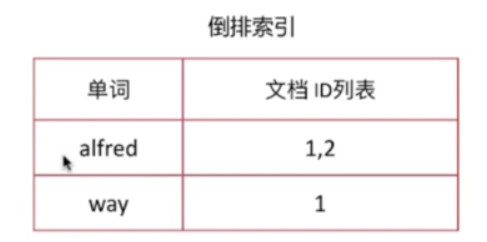
相关性算分的几个重要概念如下:
- Term Frequency(TF) 词频, 即单词在该文档中出现的次数, 词频越高, 相关度越高
- Document Frequency(DF) 文档频率, 即单词出现的文档数
- Inverse Document Frequency(IDF) 逆向文档频率, 与文档频率相反, 简单理解为1/DF, 即单词出现的文档数越少, 相关度越高
- Filed-length Norm 文档越短, 相关性越高
ES目前主要有两个相关性算分模型, 如下:
- TF/IDF 模型
- BM25模型 5.x之后的默认模型
TF/IDF 模型是Lucene的经典模型, 其计算公式如下:
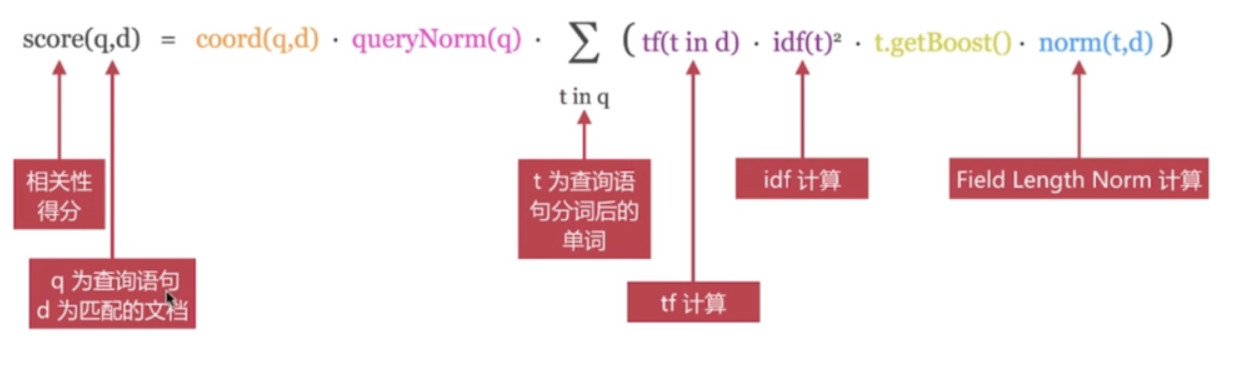
可以通过explain参数来查看具体的计算方法, 但要注意:
- ES算分是按照shard进行的, 即shard的分数计算是相互独立的, 所以在使用explain的时候注意分片数
- 可以通过设置索引的分片数为1来避免这个问题

BM25模型中BM是指Best Match, 25指迭代了25次才计算方法, 是针对TF/IDF 的一个优化, 其计算公式如下:
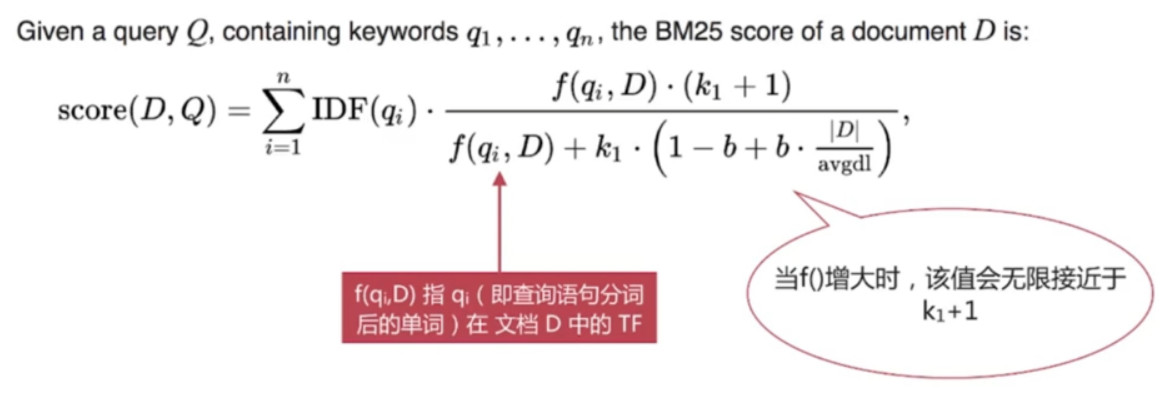
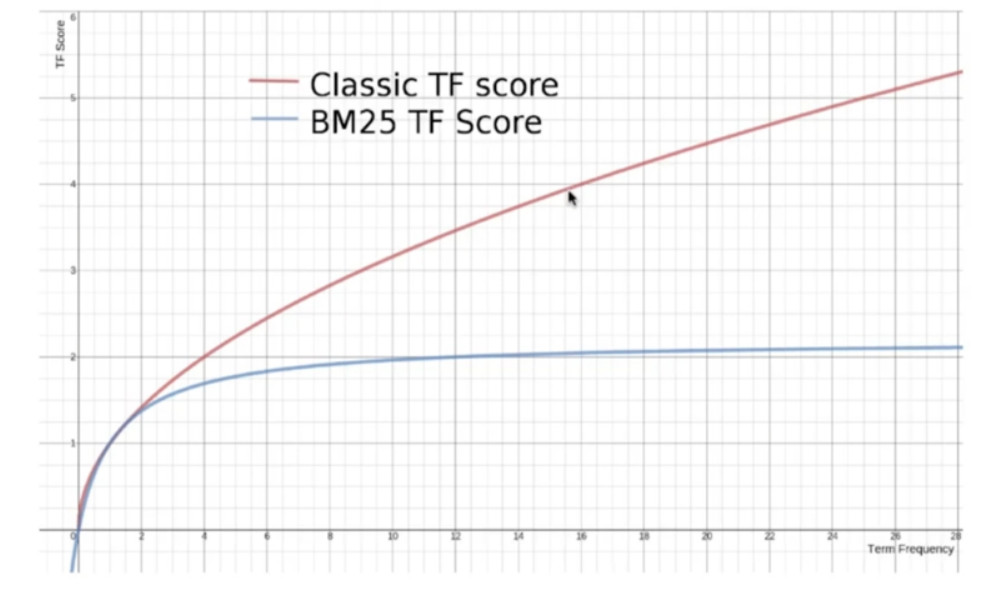
BM25相比TF/IDF的一大优化是降低了tf在过大时的权重
Match Phrase Query
对字段做检索, 有顺序要求, API示例如下:

# 和match区别如下:
# request
GET /test_search_index/_search
{
"query": {
"match_phrase": {
"job": "java engineer"
}
}
}
# response
{
"took": 20,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.5753642,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
}
]
}
}
# request
GET /test_search_index/_search
{
"query": {
"match": {
"job": "java engineer"
}
}
}
# response
{
"took": 23,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 0.986936,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "2",
"_score": 0.986936,
"_source": {
"username": "alfred",
"job": "java senior engineer and java specialist",
"age": 28,
"birth": "1980-05-07",
"isMarried": true
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.5753642,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "3",
"_score": 0.5753642,
"_source": {
"username": "lee",
"job": "java and ruby engineer",
"age": 22,
"birth": "1985-08-07",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "4",
"_score": 0.22920427,
"_source": {
"username": "alfred junior way",
"job": "ruby engineer",
"age": 23,
"birth": "1989-08-07",
"isMarried": false
}
}
]
}
}通过slop参数可以控制单词间的间隔
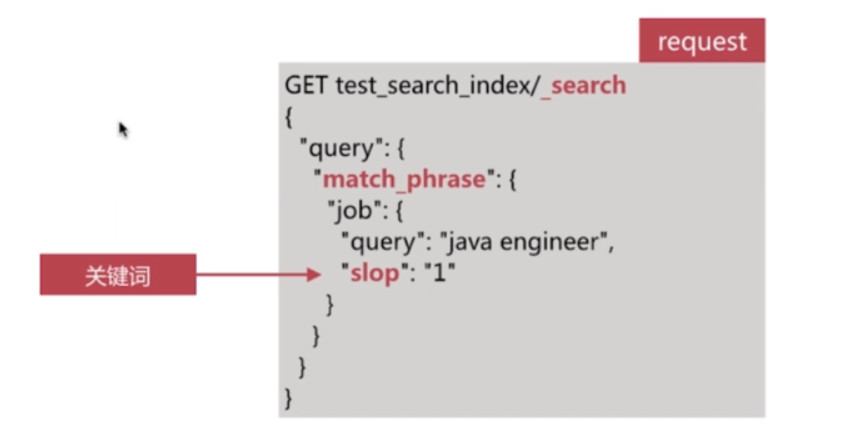
# request
GET /test_search_index/_search
{
"query": {
"match_phrase": {
"job": {
"query": "java engineer",
"slop": 2
}
}
}
}
# response
{
"took": 13,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 0.5753642,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 0.5753642,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "2",
"_score": 0.4479142,
"_source": {
"username": "alfred",
"job": "java senior engineer and java specialist",
"age": 28,
"birth": "1980-05-07",
"isMarried": true
}
}
]
}
}Query String Query
类似于URI Search 中的
q参数查询
# request
GET test_search_index/_search
{
"query": {
"query_string": {
"default_field": "job",
"query": "java AND ruby"
}
}
}
# response
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.5753642,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "3",
"_score": 0.5753642,
"_source": {
"username": "lee",
"job": "java and ruby engineer",
"age": 22,
"birth": "1985-08-07",
"isMarried": false
}
}
]
}
}- fileds指定默认查询的字段数组
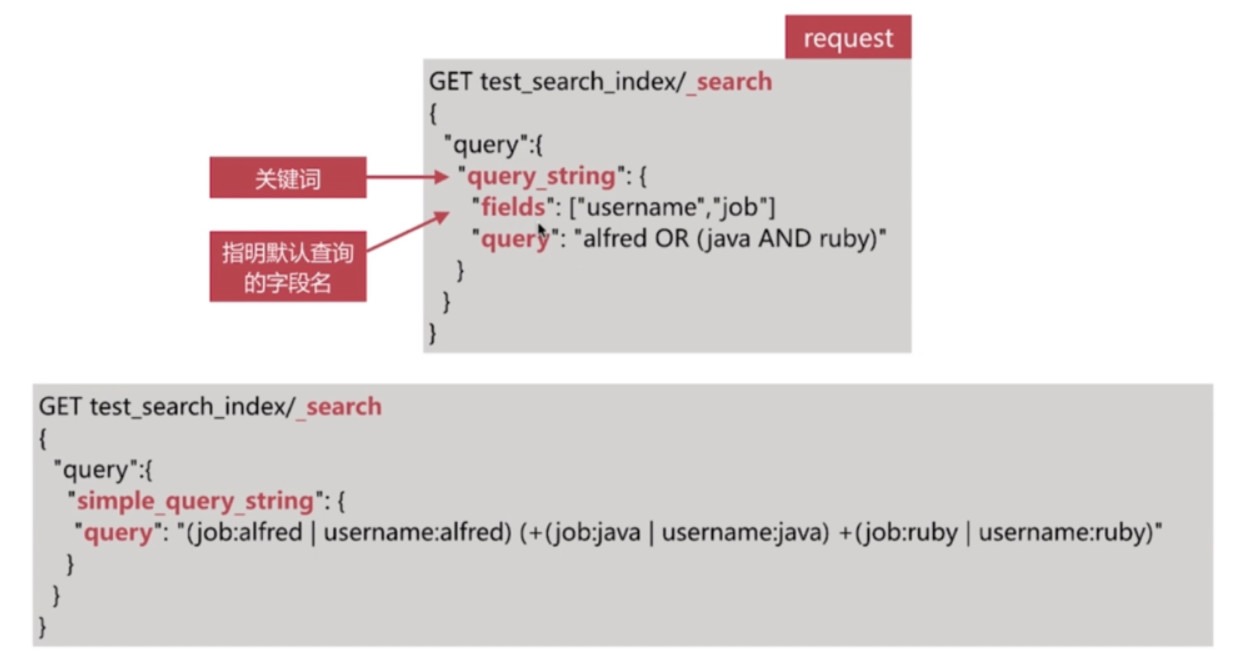
Simple Query String Query
类似Query String, 但是会忽略错误的查询语法, 并且仅支持部分查询语法
其常用的逻辑符号如下, 不能使用AND, OR, NOT等关键词:
+代指ANd|代指OR-代指NOT

Term/Terms Query
term Query
- 将查询语句作为整个单词进行查询, 即不对查询语句做分词处理, 如下所示:

# request GET test_search_index/_search { "query": { "term": { "username": "alfred way" } } }
response
注意:没有匹配到是因为在写入文档时, 进行倒排索引时进行分词, 故倒排索引的单词词典没有完整
的”alfred way”, 故没有匹配到任何文档
{
“took”: 5,
“timed_out”: false,
“_shards”: {
“total”: 5,
“successful”: 5,
“skipped”: 0,
“failed”: 0
},
“hits”: {
“total”: 0,
“max_score”: null,
“hits”: []
}
}
- terms Query
- 一次传入多个单词进行查询, 如下所示:
<img src="https://i.loli.net/2020/04/10/p3cVruRPbkMiZmh.jpg" alt="2020-04-10_040339" style="zoom:67%;" />
###### Range Query
- 范围查询主要针对数值和日期类型, 如下所示:

- 针对日期做查询如下:

- Date Math
- 针对日期提供一种更友好的计算方式, 格式如下:
<img src="https://i.loli.net/2020/04/10/jG3Hp8FPxECO6W7.jpg" alt="2020-04-10_041526" style="zoom:50%;" />
- 假设now为`2018-01-02 12:00:00`, n那么计算结果实际为:
<img src="https://i.loli.net/2020/04/10/4hSVZkCbPA2QqUu.jpg" alt="2020-04-10_041701" style="zoom:80%;" />
##### 复合查询
- 复合查询是指包含字段类查询或者复合查询的类型, 主要包括以下几类:
- constant_score query
- bool query
- dis_max query
- function_score query
- boosting query
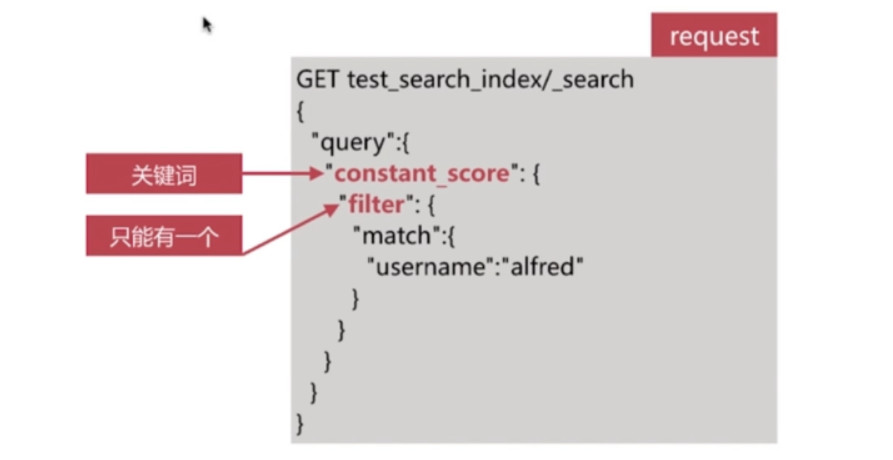
###### Constant Score Query
- 该查询将其内部的查询结果文档得分都设定为1或者boost的值
- 多用于结合bool查询实现自定义得分
```shell
# request
GET test_search_index/_search
{
"query": {
"constant_score": {
"filter": {
"match": {
"username": "alfred"
}
},
"boost": 1.2
}
}
}
# response
{
"took": 19,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1.2,
"hits": [
{
"_index": "test_search_index",
"_type": "doc",
"_id": "2",
"_score": 1.2,
"_source": {
"username": "alfred",
"job": "java senior engineer and java specialist",
"age": 28,
"birth": "1980-05-07",
"isMarried": true
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "4",
"_score": 1.2,
"_source": {
"username": "alfred junior way",
"job": "ruby engineer",
"age": 23,
"birth": "1989-08-07",
"isMarried": false
}
},
{
"_index": "test_search_index",
"_type": "doc",
"_id": "1",
"_score": 1.2,
"_source": {
"username": "alfred way",
"job": "java engineer",
"age": 18,
"birth": "1990-01-02",
"isMarried": false
}
}
]
}
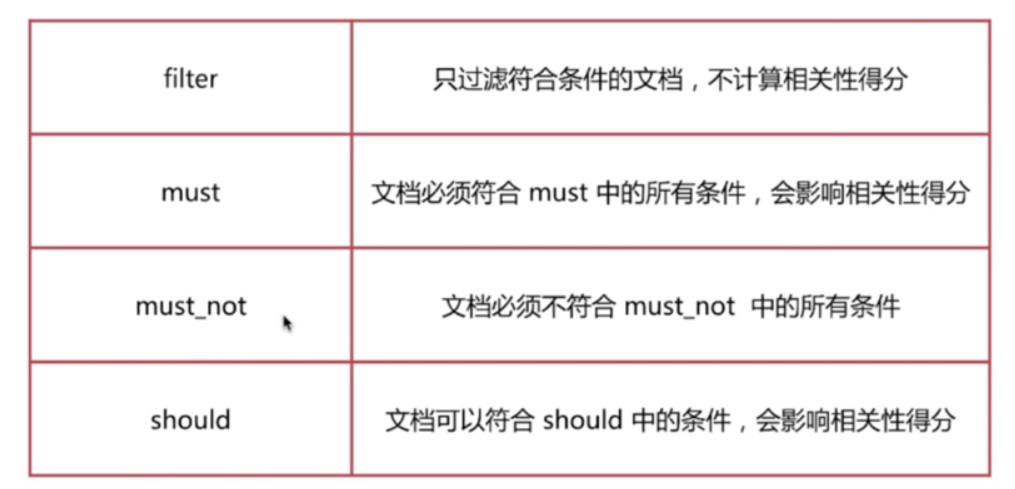
}Bool Query
布尔查询由一个或多个布尔子句组成, 主要包含如下4个:
Bool查询的API如下所示:

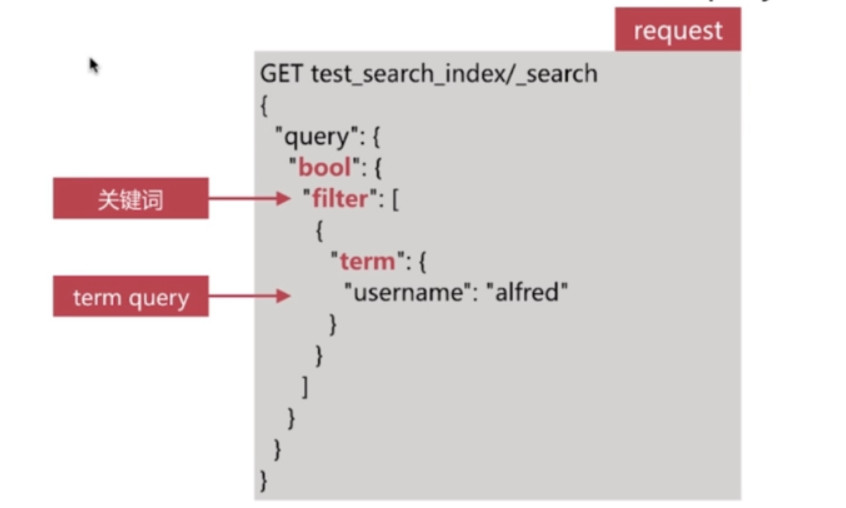
Bool Query - Filter
Filter查询只过滤符合条件的文档, 不会进行相关性算分
es针对Filter会做只能缓存, 因此其执行效率很高
做简单匹配查询且不考虑算分时, 推荐使用Filter替代query等
Bool Query - Must
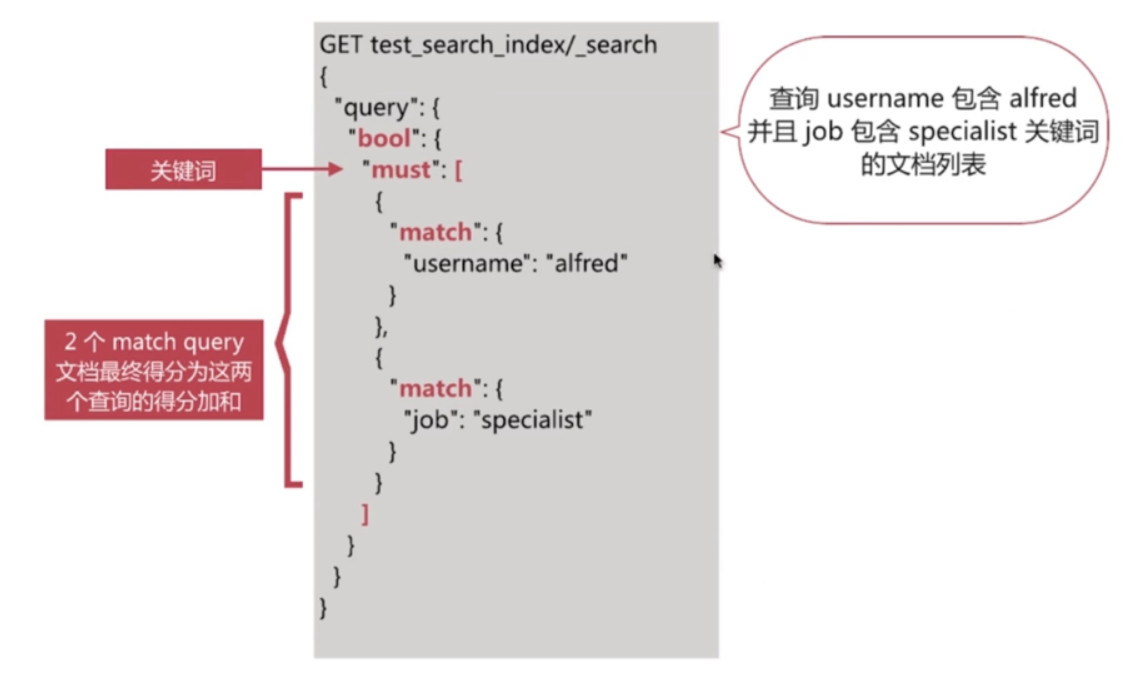
Bool Query - Should
should分两种情况:
- bool查询中只包含should, 不包含must查询
- bool查询中同时包含should和must查询
只包含should是, 文档必须满足至少一个条件
- minimum_should_match 可以控制满足条件的个数或者百分比

同时包含should和must时, 文档不必满足should中的条件, 但是如果满足条件, 会增加相关性得分

Query Context VS Filter Context
当一个查询语句位于Query 或者Filter上下文时, es执行的结果会不同, 对比如下:
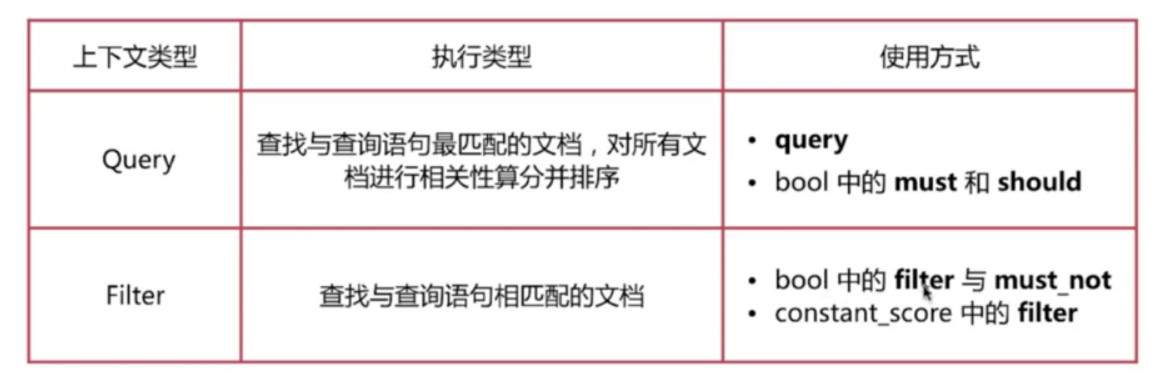
- 故利用这两种的优势, 在进行相关性算分的字段使用query, 不计算相关性算分使用filter,可以增加效率

Count API
获取符合条件的文档数, endpoint为
_count, 当只想获得文档数时使用可以节省网络开销
Source Filtering
- 过滤返回结果中
_source中的字段, 主要有如下几种方式:




