消息如何保证100%的投递成功?
什么是生产端的可靠性投递?
- 保障消息的成功发出
- 保障MQ节点的成功接收
- 发送端收到MQ节点(Broker)确认应答
- 完善的消息进行补偿机制
生产端可靠性投递——之BAT/TMD互联网大厂的解决方案
消息落库,对消息状态进行打标
消息的延迟投递,做二次确认,回调检查
具体使用哪种要根据业务场景和并发量、数据量大小来决定
方案一: 消息信息落库,对消息状态进行打标
消息信息落库,对消息状态进行打标的方案如下图所示:
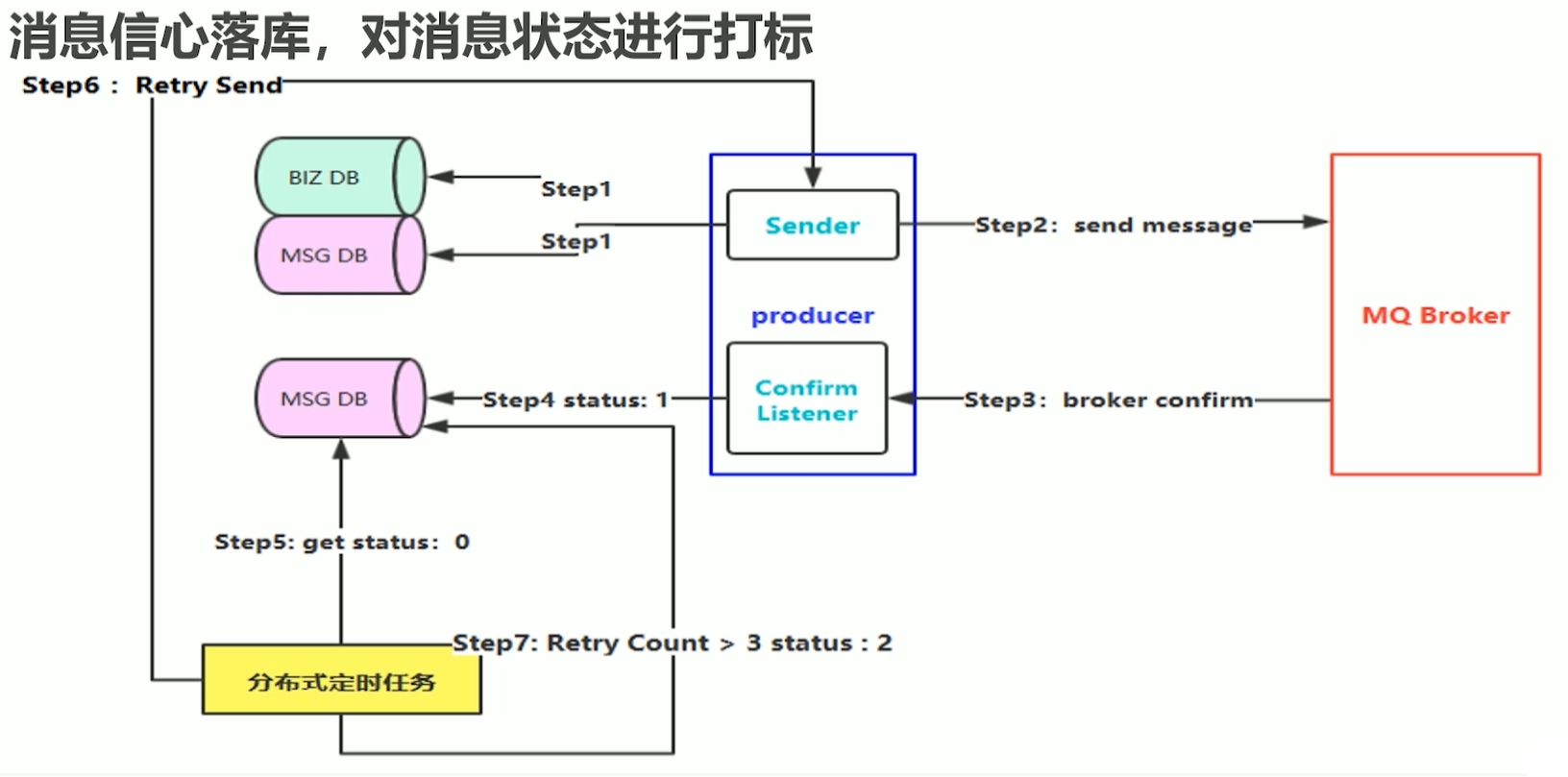
具体步骤如下:
Step 1:进行业务数据入库:比如发送一条订单消息,首先把业务数据也就是订单信息进行入库,然后生成一
条消息,把消息也进行入库,这条消息应该包含消息状态属性,并设置初始值比如为0,表示消息创建成功正在
发送中,这种方式缺陷在于我们要对数据库进行持久化两次。Step 2:首先要保证第一步消息都存储成功了,没有出现任何异常情况,然后生产端再进行消息发送。如果失
败了就进行快速失败机制。Step 3:MQ把消息收到的结果应答(confirm)给生产端。
Step 4:生产端有一个Confirm Listener,去异步的监听Broker回送的响应,从而判断消息是否投递成功,
如果成功,去数据库查询该消息,并将消息状态更新为1,表示消息投递成功。假设step 2 已经OK了,在第三步回送响应时,网络突然出现了闪断,导致生产端的Listener收不到这条
消息的confirm应答,也就是说这条消息的状态一直为0了。Step 5:此时我们需要设置一个规则,比如说消息在入库时候设置一个临界值timeout,5分钟之后如果状态还
是0,那就需要把消息抽取出来。这里,使用分布式定时任务,去定时抓取DB中距离消息创建时间超过5分钟的且
状态为0的消息。Step 6:把抓取出来的消息进行重新投递(Retry Send),也就是从Step 2开始继续往下走。
Step 7:当然有些消息可能由于一些实际的问题无法路由到Broker,比如routingKey设置不对,对应的队列
被误删除了,这种消息即使重试多次也仍然无法投递成功,所以需要对重试次数做限制,比如限制3次,如果投
递次数大于3次,那么就将消息状态更新为2,表示这个消息最终投递失败。本方案的局限性:
对于本方案,需要做两次数据库的持久化操作,在高并发场景下数据库将存在性能瓶颈。其实在核心链路
中只需要对业务数据进行入库,消息没必要先入库,可以做一个消息的延迟投递,做二次确认,回调检查。
方案二:消息的延迟投递,做二次确认,回调检查
消息的延迟投递,做二次确认,回调检查的方案如下图所示:
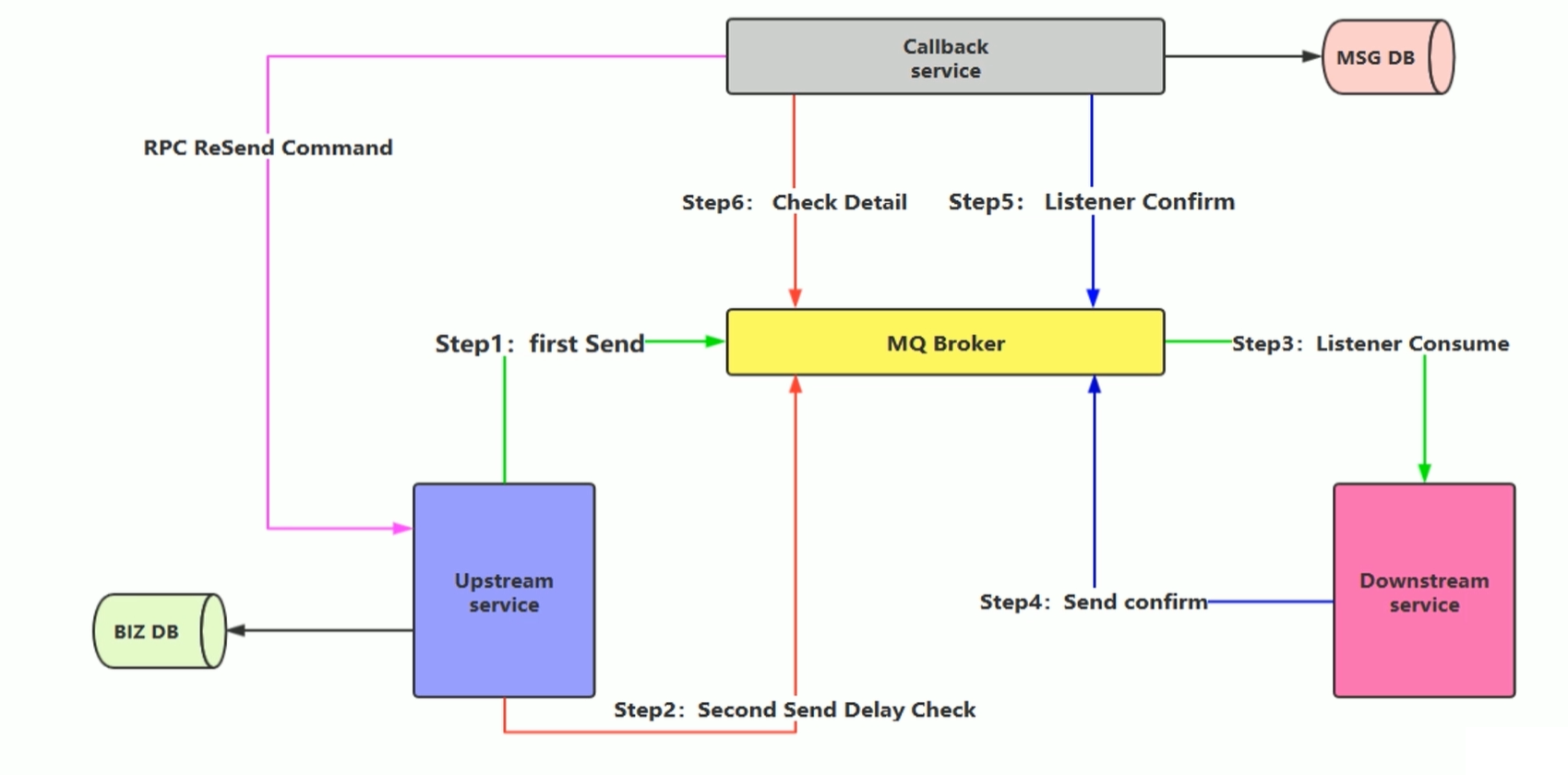
具体步骤如下:
Upstream Service(上游服务,即:生产端),Downstream service(下游服务即:消费端),Callback service(回调服务)。
- Step1:先将业务消息进行入库,然后生产端将消息发送出去,注意一定是等数据库操作完成:之后再去发
送消息。
- Step 2:在发送消息之后,紧接着生产端再次发送一条消息(Second Send Delay Check),即延迟消息投递
检查,这里需要设置一个延迟时间,比如5分钟之后进行投递。
- Step 3:消费端去监听指定队列,将收到的消息进行处理。
- Step 4:处理完成之后,发送一个confirm消息,也就是回送响应,但是这里响应不是正常的ACK,而是重新
生成一条消息,投递到MQ中。
- Step 5:上面的Callback service是一个单独的服务,其实它扮演了方案一的存储消息的DB角色,它通过MQ
去监听下游服务发送的confirm消息,如果Callback service收到confirm消息,那么就对消息做持久化存
储,即将消息持久化到DB中。
Step6:5分钟之后延迟消息发送到MQ了,然后Callback service还是去监听延迟消息所对应的队列,收到
Check消息后去检查DB中是否存在消息,如果存在,则不需要做任何处理,如果不存在或者消费失败了,那么
Callback service就需要主动发起RPC通信给上游服务,告诉它延迟投递的这条消息没有找到,需要重新发
送,生产端收到信息后就会重新查询业务消息然后将消息发送出去。本方案的优势与劣势:
方案二也是互联网大厂更为经典和主流的解决方案
方案二不一定能保障百分百投递成功,但是基本上可以保障大概99.9%的消息是OK的,有些特别极端的情
况只能是人工去做补偿了,或者使用定时任务去做。方案二主要目的是为了减少数据库操作,提高并发量。 在高并发场景下,最关心的不是消息100%投递成功,
而是一定要保证性能,保证能抗得住这么大的并发量。所以能减少数据库的操作就尽量减少,可以异步的进行
补偿。其实在主流程里面是没有这个Callback service的,它属于一个补偿的服务,整个核心链路就是生产端入
库业务消息,发送消息到MQ,消费端监听队列,消费消息。其他的步骤都是一个补偿机制。
消费端-幂等性保障
在海量订单产出的业务高峰期,如何避免消息的重复消费问题?
消费端实现幂等性,就意味着,我们的消息永远不会消费多次,即使我们收到多条一样的消息
主流的幂等性操作
唯一ID+指纹码 ,利用数据库主键去重
好处:实现简单
坏处:高并发下有DB写入的性能瓶颈
解决方案:跟进ID进行分库分表进行算法路由利用Redis的原子性去实现幂等,需要考虑的问题?
1、我们是否进行数据落库,如果落库的话,关键解决的问题是数据库和缓存如何做到原子性?
2、如果不落库,存储到缓存中,如何设置定时同步的策略?
深入理解幂等性
###什么是幂等性
HTTP/1.1中对幂等性的定义是:一次和多次请求某一个资源对于资源本身应该具有同样的结果(网络超时等
问题除外)。也就是说,其任意多次执行对资源本身所产生的影响均与一次执行的影响相同。
Methods can also have the property of “idempotence” in that (aside from error or
expiration issues) the side-effects of N > 0 identical requests is the same as for a
single request.
这里需要关注几个重点:
幂等不仅仅只是一次(或多次)请求对资源没有副作用(比如查询数据库操作,没有增删改,因此没有对数
据库有任何影响)。幂等还包括第一次请求的时候对资源产生了副作用,但是以后的多次请求都不会再对资源产生副作用。
幂等关注的是以后的多次请求是否对资源产生的副作用,而不关注结果。
网络超时等问题,不是幂等的讨论范围。
幂等性是系统服务对外一种承诺(而不是实现),承诺只要调用接口成功,外部多次调用对系统的影响是一
致的。声明为幂等的服务会认为外部调用失败是常态,并且失败之后必然会有重试。
什么情况下需要幂等
业务开发中,经常会遇到重复提交的情况,无论是由于网络问题无法收到请求结果而重新发起请求,或是前
端的操作抖动而造成重复提交情况。 在交易系统,支付系统这种重复提交造成的问题有尤其明显,比如:
用户在APP上连续点击了多次提交订单,后台应该只产生一个订单;
向支付宝发起支付请求,由于网络问题或系统BUG重发,支付宝应该只扣一次钱。 很显然,声明幂等的服务认为,外部调用者会存在多次调用的情况,为了防止外部多次调用对系统数据状态的发生多次改变,将服务设计成幂等。
幂等VS防重
上面例子中遇到的问题,只是重复提交的情况,和服务幂等的初衷是不同的。重复提交是在第一次请求已经
成功的情况下,人为的进行多次操作,导致不满足幂等要求的服务多次改变状态。而幂等更多使用的情况是第
一次请求不知道结果(比如超时)或者失败的异常情况下,发起多次请求,目的是多次确认第一次请求成功,
却不会因多次请求而出现多次的状态变化。什么情况下需要保证幂等性
以SQL为例,有下面三种场景,只有第三种场景需要开发人员使用其他策略保证幂等性:
SELECT col1 FROM tab1 WHER col2=2,无论执行多少次都不会改变状态,是天然的幂等。
UPDATE tab1 SET col1=1 WHERE col2=2,无论执行成功多少次状态都是一致的,因此也是幂等操作。
UPDATE tab1 SET col1=col1+1 WHERE col2=2,每次执行的结果都会发生变化,这种不是幂等的。
为什么要设计幂等性的服务
幂等可以使得客户端逻辑处理变得简单,但是却以服务逻辑变得复杂为代价。满足幂等服务的需要在逻辑中
至少包含两点:首先去查询上一次的执行状态,如果没有则认为是第一次请求
在服务改变状态的业务逻辑前,保证防重复提交的逻辑
幂等的不足
幂等是为了简化客户端逻辑处理,却增加了服务提供者的逻辑和成本,是否有必要,需要根据具体场景具体
分析,因此除了业务上的特殊要求外,尽量不提供幂等的接口。增加了额外控制幂等的业务逻辑,复杂化了业务功能;
把并行执行的功能改为串行执行,降低了执行效率。
保证幂等策略
幂等需要通过唯一的业务单号来保证。也就是说相同的业务单号,认为是同一笔业务。使用这个唯一的业务
单号来确保,后面多次的相同的业务单号的处理逻辑和执行效果是一致的。 下面以支付为例,在不考虑并发的
情况下,实现幂等很简单:①先查询一下订单是否已经支付过,②如果已经支付过,则返回支付成功;如果没有
支付,进行支付流程,修改订单状态为‘已支付’。
防重复提交策略
上述的保证幂等方案是分成两步的,第②步依赖第①步的查询结果,无法保证原子性的。在高并发下就会出现
下面的情况:第二次请求在第一次请求第②步订单状态还没有修改为‘已支付状态’的情况下到来。既然得出了这
个结论,余下的问题也就变得简单:把查询和变更状态操作加锁,将并行操作改为串行操作。
乐观锁
如果只是更新已有的数据,没有必要对业务进行加锁,设计表结构时使用乐观锁,一般通过version来做乐观
锁,这样既能保证执行效率,又能保证幂等。例如: UPDATE tab1 SET col1=1,version=version+1
WHERE version=#version# 不过,乐观锁存在失效的情况,就是常说的ABA问题,不过如果version版本一直
是自增的就不会出现ABA的情况。(从网上找了一张图片很能说明乐观锁,引用过来,出自Mybatis对乐观锁的
支持)
防重表
使用订单号orderNo做为去重表的唯一索引,每次请求都根据订单号向去重表中插入一条数据。第一次请求查询
订单支付状态,当然订单没有支付,进行支付操作,无论成功与否,执行完后更新订单状态为成功或失败,删
除去重表中的数据。后续的订单因为表中唯一索引而插入失败,则返回操作失败,直到第一次的请求完成(成
功或失败)。可以看出防重表作用是加锁的功能。
分布式锁
这里使用的防重表可以使用分布式锁代替,比如Redis。订单发起支付请求,支付系统会去Redis缓存中查询是
否存在该订单号的Key,如果不存在,则向Redis增加Key为订单号。查询订单支付已经支付,如果没有则进行
支付,支付完成后删除该订单号的Key。通过Redis做到了分布式锁,只有这次订单订单支付请求完成,下次请
求才能进来。相比去重表,将放并发做到了缓存中,较为高效。思路相同,同一时间只能完成一次支付请求。
token令牌
这种方式分成两个阶段:申请token阶段和支付阶段。 第一阶段,在进入到提交订单页面之前,需要订单系统
根据用户信息向支付系统发起一次申请token的请求,支付系统将token保存到Redis缓存中,为第二阶段支付
使用。 第二阶段,订单系统拿着申请到的token发起支付请求,支付系统会检查Redis中是否存在该token,如
果存在,表示第一次发起支付请求,删除缓存中token后开始支付逻辑处理;如果缓存中不存在,表示非法请
求。 实际上这里的token是一个信物,支付系统根据token确认,你是你妈的孩子。不足是需要系统间交互两
次,流程较上述方法复杂。
支付缓冲区
把订单的支付请求都快速地接下来,一个快速接单的缓冲管道。后续使用异步任务处理管道中的数据,过滤掉
重复的待支付订单。优点是同步转异步,高吞吐。不足是不能及时地返回支付结果,需要后续监听支付结果的
异步返回。




